Búsqueda de información profesional en Internet. Software y servicios para la búsqueda de profesionales. Reglas de ejecución de consultas
Encontrar la información correcta y actualizada en Internet a veces es muy difícil. La cantidad de basura informativa en la Web está creciendo como una bola de nieve y, a veces, es simplemente imposible obtener los datos que realmente necesita utilizando Yandex tradicional y Google. El libro que tiene en sus manos aumentará muchas veces la eficiencia de su búsqueda de información en Internet. Describe técnicas, sitios de búsqueda y programas para la recuperación de información especializada. Se consideran variedades modernas de búsqueda en Internet: búsqueda universal, búsqueda vertical, sistemas de metabúsqueda, creación de motores de búsqueda personales, búsqueda de contenido audiovisual, búsqueda en la Internet oculta. Para todos los sistemas considerados, se dan sus características y consejos para el uso más eficiente.
Introducción
La búsqueda en Internet es un elemento importante del trabajo en la Web. El número exacto de recursos web internet moderno casi nadie lo sabe con certeza. En cualquier caso, la factura asciende a miles de millones. Para poder utilizar la información que se necesita en este momento en particular, ya sea con fines comerciales o de entretenimiento, primero debe encontrarla en este océano de recursos que se renueva constantemente. Esta no es una tarea nada fácil, ya que la información en web moderna no estructurado, lo que crea problemas para encontrarlo. No es casualidad que los buscadores de Internet se hayan convertido en una especie de “ventanas” a este espacio de información.
Es poco probable que entre los usuarios de Internet haya personas que nunca hayan utilizado grandes motores de búsqueda universales. Los nombres Google, Yandex y un par de otras grandes máquinas están en boca de todos. Hacen un excelente trabajo en las tareas diarias de búsqueda en Internet y, a menudo, los usuarios ni siquiera intentan buscar un reemplazo para ellos. Al mismo tiempo, la cantidad de motores de búsqueda en Internet en nuestro tiempo es de miles. Las razones de tal variedad de máquinas alternativas tienen varias raíces. Algunos proyectos están tratando de competir directamente con los líderes del mercado global a través de un trabajo cuidadoso con los recursos nacionales de Internet. Otros ofrecen funciones de consulta que no se encuentran en los motores de búsqueda establecidos. Un número significativo de máquinas alternativas se especializan en buscar un área temática en particular o un tipo de contenido en particular, logrando resultados impresionantes en la solución de estos problemas. Sea como fuere, la inclusión de dichos motores de búsqueda en el propio arsenal de herramientas de búsqueda en Internet del usuario puede mejorar significativamente su calidad. Aquí, sin embargo, hay un matiz: debe conocer tales máquinas y poder usar sus capacidades.
Suponemos que los lectores de este libro ya están bastante familiarizados con la técnica de búsqueda utilizando motores de búsqueda universales. Tan bueno que sintieron las limitaciones asociadas con su uso. Lo más probable es que esas personas ya hayan intentado buscar y aplicar ciertas herramientas adicionales. La palabra impresa no pasa por alto el tema de la búsqueda en Internet: periódicamente aparecen tanto artículos como libros. Pero los héroes que tienen, por regla general, son los mismos: varios motores de búsqueda universales líderes. Nuestro libro es diferente porque intenta cubrir la gama completa de soluciones de búsqueda modernas. Aquí encontrará descripciones y recomendaciones para utilizar los mejores servicios modernos enfocados en resolver las tareas de búsqueda más comunes. Este libro es para personas que trabajan mucho en Internet y usan la Web para encontrar la información que necesitan, ya sea para negocios, estudios o pasatiempos.
Para que una búsqueda en Internet tenga éxito, se deben cumplir dos condiciones: las consultas deben estar bien formuladas y deben realizarse en lugares adecuados. En otras palabras, se requiere que el usuario, por un lado, sea capaz de traducir sus intereses de búsqueda al idioma de la consulta de búsqueda y, por otro lado, un buen conocimiento de los motores de búsqueda, las herramientas de búsqueda disponibles, sus ventajas y inconvenientes, que permitirán elegir las herramientas de búsqueda más adecuadas en cada caso concreto.
Actualmente, no existe un recurso que satisfaga todos los requisitos para la búsqueda en Internet. Por lo tanto, con un enfoque serio de la búsqueda, inevitablemente debe usar diferentes herramientas, usando cada una en el caso más apropiado.
Capítulo 1
Motores de búsqueda universales en Internet
Los motores de búsqueda universales en Internet son el principal y más conocido medio de búsqueda en Internet. Dichos motores de búsqueda brindan la máxima cobertura de diversos recursos. Es el tipo universal que incluye los motores de búsqueda más grandes y populares. Estas son soluciones realmente poderosas con muchas funciones y herramientas que muchos usuarios a menudo desconocen. Comprender las características y capacidades de la búsqueda universal le permite descubrir las fortalezas y debilidades de dichos sistemas y elegir conscientemente las herramientas de búsqueda más efectivas.
El mercado de los motores de búsqueda universales es bastante grande. En este capítulo, consideraremos solo las máquinas más poderosas que pueden trabajar adecuadamente con consultas en ruso. El capítulo comienza con historias sobre los líderes de la búsqueda rusa: los sistemas Google.ru y Yandex. Se han escrito libros y muchos artículos sobre cada uno de estos motores de búsqueda. Nos centraremos en las principales características que son importantes para el usuario final y también intentaremos identificar sus puntos fuertes.
Están acompañados por un nuevo desarrollo de búsqueda de Microsoft Corporation: el sistema Bing, que hasta ahora no ha recibido mucha atención, así como un motor de búsqueda útil y bastante potente, Exalead, cuya ventaja es un buen soporte de búsqueda en los recursos de Internet europeos. . Este sistema sigue siendo un invitado raro en el arsenal de búsqueda de nuestros usuarios, por lo que se considera con más detalle que los demás.
En este capítulo, al revisar sistemas de google y Yandex, nos centraremos solo en las capacidades de búsqueda web, y la búsqueda en bases de datos especializadas de estos proyectos se analiza en los siguientes capítulos sobre búsqueda de imágenes y videos. Para otros motores de búsqueda universales, la información sobre la búsqueda multimedia se proporciona inmediatamente después de familiarizarse con ellos.
Dado que tres de los cuatro héroes de este capítulo son de origen extranjero, notamos de inmediato que estamos analizando las posibilidades de solo sus versiones rusas. El hecho es que algunas funciones de los sistemas extranjeros, especialmente los experimentales, a menudo están disponibles solo en las versiones originales, por regla general, de los servicios en inglés.
El motor de búsqueda de Google es merecidamente considerado el líder mundial en la búsqueda moderna de Internet. Fundada en 1998 Google hasta el día de hoy se mantiene entre los principales creadores de tendencias en el campo de la búsqueda en Internet y los servicios web.
Los desarrolladores de Google siempre se han distinguido por una mayor atención a la mejora de los algoritmos de su motor de búsqueda, así como por un conservadurismo razonable en la interfaz de usuario. Las posibilidades de compilar una consulta en Google pueden llamarse clásicas, y las formas de mostrar los resultados de búsqueda también se han convertido en una especie de estándar. V Últimamente Los desarrolladores de Google han realizado cambios importantes en estas áreas: el motor de búsqueda más grande comenzó a verse demasiado anticuado en el contexto de los competidores jóvenes.
Google tiene una de las bases de índices más grandes del mundo, que brinda una amplia cobertura de fuentes de información. La información del índice de Google se resume en varias bases verticales. Además de la base de datos Web más famosa, existen varias bases de datos multimedia (Imágenes, Videos) que funcionan con fuentes de información y mensajes relevantes en fuentes RSS, la base de datos de Noticias, así como la base de datos de Blogs que indexa diarios en línea. Además, Google ofrece amplia elección recursos adicionales, entre los que cabe destacar el servicio cartográfico, el directorio de sitios, el servicio de preguntas y respuestas. Estos recursos también se pueden considerar como herramientas de búsqueda.
En la base de datos web, Google ofrece modos de búsqueda simples y avanzados para compilar una consulta. En el modo de búsqueda simple, solo el teclado virtual está disponible desde herramientas adicionales. La búsqueda avanzada ofrece más opciones. Dado que el formulario de búsqueda avanzada está disponible en casi todos los productos de búsqueda de Google, detengámonos en él con más detalle (Fig. 1.1).
Yandex
Presentado oficialmente al público en general en 1997, el motor de búsqueda Yandex se desarrolló con éxito y diez años después, por primera vez, se encontraba entre los diez motores de búsqueda más grandes del mundo. En el segmento ruso de Internet, ha logrado una posición de liderazgo, a la que no va a renunciar, a pesar de la creciente competencia. Características distintivas Desde el comienzo de su existencia, Yandex se ha convertido en sus propios algoritmos originales para determinar la relevancia de los resultados de búsqueda, herramientas flexibles para trabajar con texto de consulta y tener en cuenta las peculiaridades de la morfología del idioma ruso al procesarlos.
Yandex se basa en sus propias bases de datos de índice. Además de buscar a través de documentos web, el sistema ofrece una buena selección de recursos especializados y servicios adicionales. Yandex actualmente trabaja con imágenes, videos, noticias, blogs y diccionarios. Las poderosas capacidades de búsqueda también están integradas en nuestro propio servicio cartográfico y en el sistema de búsqueda de productos. Además, Yandex mantiene su propio catálogo de sitios web. Punto fuerte Yandex es un programa de búsqueda local desarrollado, que es especialmente importante para nuestros usuarios. Yandex proporciona acceso a sus bases de datos a desarrolladores externos. Como resultado, muchos proyectos de búsqueda de Internet alternativos rusos utilizan los recursos de Yandex de una forma u otra. Además del sistema de búsqueda habitual, también se ofrece una versión abreviada de Yandex, disponible en ya.ru. La interfaz de esta versión consta únicamente de un campo de entrada de consulta y un botón de inicio de búsqueda.
La búsqueda de documentos web ofrece modos de búsqueda simples y avanzados. La búsqueda simple no proporciona ningún filtro, lo que se compensa con la capacidad de analizar automáticamente las consultas en lenguaje natural, el procesamiento confiable de consultas relativamente largas y un sistema automático de finalización de consultas. La longitud máxima de la consulta es de cuarenta palabras.
El formulario de búsqueda avanzada para redactar una consulta ofrece un solo campo. Se sugiere que los operadores lógicos que vinculan las palabras de consulta se ingresen manualmente, bien. Yandex tiene un lenguaje de consulta bastante detallado. El resto de herramientas del formulario de búsqueda avanzada son varios filtros (1.4).
bing
El historial de búsqueda de Internet de Microsoft no es fácil de llamar. Los servicios que se ofrecen constantemente al público han cambiado repetidamente los algoritmos, las bases de datos utilizadas y, por supuesto, los nombres. Hasta principios de la década de 2000, el buscador no contaba con bases de datos propias y trabajaba con índices externos de AltaVista, Inktomi y Looksmart. El nombre original MSN Search se usó hasta 2006 y luego, durante varios años, cambiar los nombres del motor de búsqueda se convirtió en una tradición para Microsoft.
Junto con la transición final para buscar en sus propios índices, MSN Search primero cambió su nombre a Windows LiveLive Search. Finalmente, a principios del verano de 2009, Live Search fue reemplazado por el nuevo proyecto de búsqueda de Bing.
“Bing proporcionará una forma diferente de ver la información en Internet y ayudará a los usuarios a tomar decisiones importantes”, comenzaba con tal declaración el comunicado de prensa de Microsoft sobre el lanzamiento de Bing. Las aspiraciones de los desarrolladores eran comprensibles: los motores de búsqueda de Microsoft, a pesar de todos los esfuerzos, en Occidente fueron constantemente inferiores en popularidad a los líderes: Google y Yahoo!. Si hablamos de las versiones en ruso de proyectos de búsqueda anteriores de Microsoft, en términos de cantidad y calidad de los enlaces encontrados, eran muy inferiores a los grandes motores de búsqueda rusos. En un intento por ponerse al día con los competidores, los desarrolladores de Bing se han basado en mejorar la calidad de la búsqueda y la introducción de nuevas tecnologías, muchas de las cuales fueron adquiridas junto con las empresas que las crearon.
se debe notar que Versión rusa Bing, como la mayoría de las otras versiones localizadas, carece de una serie de funciones adicionales, como la búsqueda de tiendas. Ya que, de hecho, solo funcionan en el norte. América, no tiene sentido detenerse en ellos en detalle.
Exalead
Una de las características de Europa, incluso en el campo de la búsqueda en Internet, es un gran número de lenguas nacionales. Un motor de búsqueda que pretende ser el líder en Europa simplemente está obligado a indexar bien los segmentos nacionales de Internet y procesar consultas en numerosos idiomas europeos, tanto los más grandes como los menos comunes, con alta calidad. Es en esta área donde el desarrollo europeo puede obtener una importante ventaja competitiva sobre los poderosos competidores extranjeros. El sistema Exalead actualmente está reclamando seriamente el papel de un motor de búsqueda europeo de este tipo. Este proyecto fue desarrollado como parte del programa de investigación Quaere financiado por la Unión Europea.
Exalead tiene sus propias bases de datos de índices. Los principales recursos de búsqueda del sistema son bases de datos de documentos web, imágenes, videos y noticias. página de inicio Exalead ofrece la posibilidad de personalización. En esta página, puede colocar enlaces a sus sitios favoritos; se mostrarán como capturas de pantalla en miniatura gráficas. Es cierto que para ello deberá registrar una cuenta de forma gratuita, así como permitir que el navegador almacene cookies de Exalead.
Exalead Web Search ofrece modos de búsqueda simples y avanzados. El formulario de búsqueda avanzada, como en Bing, se abre directamente en la página de emisión. Tenga en cuenta que Exalead ofrece no solo un formulario familiar con un conjunto de campos adicionales, sino también un menú desplegable complejo que actúa como un asistente para refinar la consulta (Fig. 1.7). Cuando selecciona uno u otro elemento en el menú del asistente, se agregan nuevos elementos a la cadena de consulta y, si es necesario, operadores y caracteres especiales.
Verificando un apodo para docenas de servicios a la vez, contando los reenvíos en Facebook y visualizando las conexiones de cuentas de Twitter.
El análisis de contenido de las redes sociales es un tema candente entre las nuevas empresas. Cada año hay más y más servicios para buscar publicaciones y personas. Pero muchos de ellos desaparecen rápidamente, están disponibles sin terminar o son costosos de usar.
Este material contiene algunos de ellos que le permiten obtener de forma rápida y gratuita información realmente útil o simplemente interesante.
1. Búsqueda de perfiles
Sistema de búsqueda soplón le permite buscar los perfiles de una persona en cuatro docenas de servicios, incluidos los sitios web de las principales universidades del mundo y la base de datos criminal de EE. UU.:
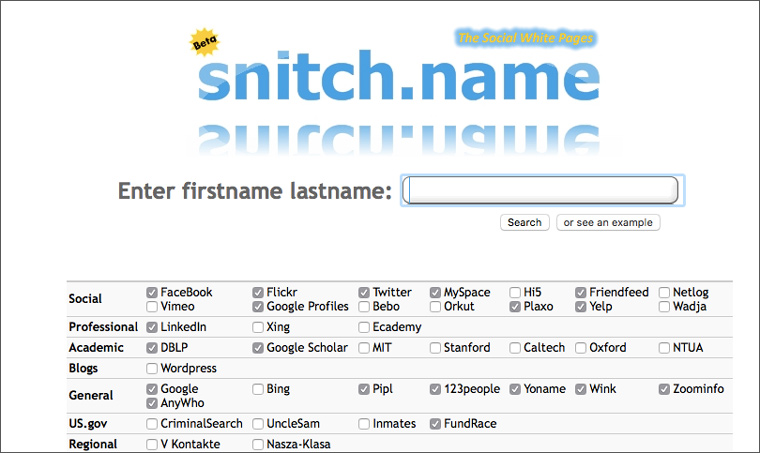
Desafortunadamente, algunos de los sitios para los que puede marcar las casillas ya no funcionan. Por ejemplo, Google Uncle Sam, cerró hace 5 años. Pero a pesar de esta y otras jambas, Snitch es un servicio útil que puede ahorrar mucho tiempo al buscar información sobre una persona.
Si para algún servicio en lugar de bloques con resultados de búsqueda se muestra una pantalla en blanco, para verlos debe seguir el enlace Abrir una nueva ventana:
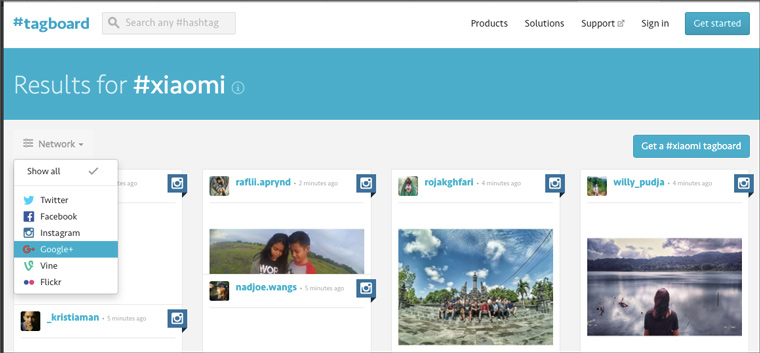
2. Busca hashtags
Es muy fácil de usar. Es necesario introducir el hashtag deseado en el formulario de búsqueda y en un segundo aparecerá una lista de entradas recientes marcadas por él en seis redes sociales:
3. Análisis de tuits recientes
El servicio le permite obtener una lista de los últimos cien tweets que contienen la palabra de búsqueda, el hashtag o el nombre de la cuenta. Y también aprende algo información analítica sobre las personas que hicieron estos tweets y cuándo se hicieron:

Supongamos que desea averiguar qué usuario provocó una cantidad inusualmente alta de clics en un artículo de Twitter. Miramos los últimos 100 tweets y vemos cuál de las personas que mencionaron el concepto original tiene más seguidores:

Una gran cantidad de tweets están disponibles para análisis de los propietarios de una suscripción paga:

4. Análisis de la cuenta de Twitter
Sobre el aplicación de mención puede ingresar el nombre de la cuenta y obtener información al respecto (quién retuitea con más frecuencia, qué hashtags usa, etc.) en forma de diagrama de enlace:

5. Busca tuits en el mapa
Si hace clic en cualquier lugar del mapa en , puede leer los últimos tweets realizados cerca:

6. El número de menciones en redes sociales
Recuento compartido ayuda a evaluar la popularidad de un artículo/sitio en las redes sociales. Entras en la URL y en un par de segundos hay estadísticas de menciones en Facebook, Google+, Pinterest, LinkedIn y Stumble Upon:

7. Foros de búsqueda
lector de tablero es un buscador de foros y tablones de anuncios:
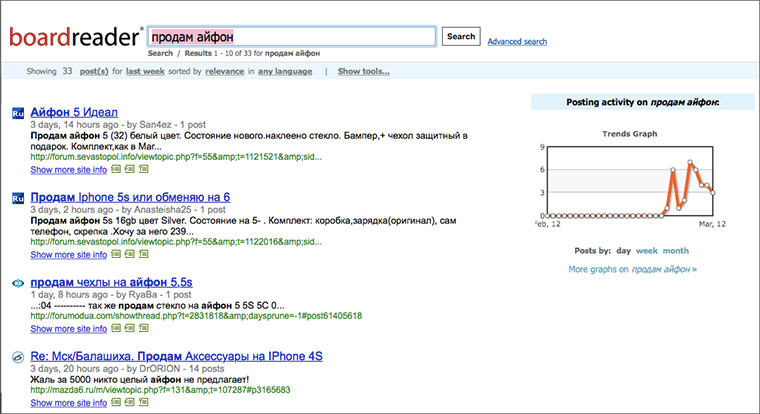

Una evaluación de la magnitud del desastre mostró que hay casi 4 respuestas en este portal por habitante de Rusia.
8. Rompemos el inicio de sesión en las redes sociales.
Vaya a knowem.com y escriba el apodo de la persona. En respuesta, recibimos información sobre en qué servicios está registrado:

9. Determinar el nombre de la persona por correo electrónico
Si todavía está buscando personas ingresando sus direcciones de correo electrónico en Google, entonces debe abandonar este método. Después de todo, existe pipl.com. Manejas en un correo electrónico (apodo) y obtienes una lista de perfiles en las redes sociales:

La información no siempre es precisa y completa, pero el servicio es excepcionalmente útil.
Eso es todo. Valió la pena hablar sobre Socialmention (análisis de revisión sin terminar), Yomapic (busque fotos de VK e Instagram en el mapa) y yandex.
A mediados de 2015, la red global de Internet ya había conectado a 3.200 millones de usuarios, es decir, casi el 43,8% de la población mundial. A modo de comparación: hace 15 años, solo el 6,5% de la población era usuario de Internet, es decir, ¡el número de usuarios aumentó en más de 6 veces! Pero más impresionantes no son los indicadores cuantitativos, sino cualitativos de la expansión de la introducción de las tecnologías de Internet en varias áreas de la actividad humana: desde las comunicaciones globales de las redes sociales hasta las cosas domésticas de Internet. Internet móvil ha hecho posible que los usuarios estén en línea fuera de la oficina y en casa: en la carretera, fuera de la ciudad, en la naturaleza.
Actualmente existen cientos de sistemas de búsqueda de información en Internet. Los más populares están disponibles para la gran mayoría de los usuarios porque son gratuitos y fáciles de usar: Google, Yandex, Nigma, Yahoo!, Bing ..... Los usuarios más experimentados tienen interfaces de "búsqueda avanzada", "redes sociales" especializadas. "búsquedas en red", según flujos de noticias y anuncios de compra y venta... Pero todos estos maravillosos buscadores tienen un importante inconveniente, que ya he apuntado como ventaja más arriba: son gratuitos.
Si los inversores invierten miles de millones de dólares en el desarrollo de motores de búsqueda, entonces surge una pregunta bastante relevante: ¿de dónde ganan dinero?
Y ganan en particular por el hecho de que proporcionan a las solicitudes de los usuarios no solo la información que sería útil desde el punto de vista del usuario, sino también la información que los propietarios de los motores de búsqueda consideran útil para el usuario. Esto se hace manipulando el orden de emisión de listas de respuestas a las consultas de búsqueda de los usuarios. Aquí y publicidad abierta de ciertos recursos de Internet, y juegos malabares ocultos de la relevancia de las respuestas en función de los intereses comerciales, políticos e ideológicos de los propietarios de los motores de búsqueda.
Por ello, entre los profesionales especialistas en la búsqueda de información en Internet, el problema de la pertinencia de los resultados de los buscadores es muy relevante.
La pertinencia es la correspondencia de los documentos encontrados por el sistema de recuperación de información con las necesidades de información del usuario, independientemente de cuán completa y precisa sea expresada esta necesidad de información en el texto de la propia solicitud de información. Esta relación de volumen información útil a la cantidad total de información recibida. En términos generales, esto es eficiencia de búsqueda.
Los especialistas que realizan una búsqueda calificada de información en Internet deben hacer ciertos esfuerzos para filtrar los resultados de la búsqueda, filtrando el "ruido" de información innecesaria. Y para ello se utilizan herramientas de búsqueda de nivel profesional.
Uno de esos sistemas profesionales es el programa ruso. FileForFiles y SiteSputnik (SiteSputnik).
Desarrollador Aleksey Mylnikov de Volgogrado.
"El programa FileForFiles & SiteSputnik (SiteSputnik) está diseñado para organizar y automatizar la búsqueda, recopilación y seguimiento profesional de información publicada en Internet. Se presta especial atención a la obtención de nueva información sobre temas de interés. Se han implementado varias funciones de análisis de información."
Seguimiento y categorización de los flujos de información
Primero, unas pocas palabras sobre monitoreo del flujo de información, un caso especial del cual es seguimiento de medios y redes sociales:
- el usuario especifica Fuentes que pueden contener Información necesaria y Reglas para seleccionar esta información;
- el programa descarga enlaces nuevos de las Fuentes, libera su contenido de basura y repeticiones, y los clasifica en Encabezados de acuerdo con las Reglas.
Para ver en vivo un proceso de monitoreo simple pero real, que involucra 6 fuentes y 4 encabezados:- abra la versión Demo del programa;
- luego, en la ventana que aparece, haga clic en el botón conjuntamente;
- y cuando SitioSputnik ejecutará este Proyecto en tiempo real, usted:
- en la lista "Clean stream" verás todos nueva información de fuentes,
— en la sección "Post-solicitud" - solo noticias económicas y financieras que cumplan la regla,
- en los Títulos "Sobre el Presidente", "Sobre el Primer Ministro" y "Banco Central" - información relacionada con los objetos respectivos.
En Proyectos reales, puede usar casi cualquier número de Fuentes y Encabezados.
Puede crear sus primeros proyectos de trabajo en unas pocas horas, su mejora está en proceso de operación.
El procesamiento de información descrito está disponible en el paquete SiteSputnik Pro+News y superior.
2. Búsqueda simple y por lotes, recopilación de información.
Para familiarizarse con las posibilidades. SitioSputnik Pro(versión básica del paquete de programas) :
- abra la versión Demo del programa;
- ingrese su primera solicitud, por ejemplo, su nombre completo, como lo hice yo:
y haga clic en el botón Búsqueda.
- El programa (vea el letrero que construyó SiteSputnik) en unos segundos interrogará 7 fuentes, descubrirá en ellas 24 paginas de busqueda, encontrará 227 enlaces relevantes eliminar enlaces redundantes y del resto 156 único los enlaces aparecerán en la lista "Una asociación".
Total: número de enlaces únicos - 156 , enlaces repetidos - 46 %.
Nombre
fuente
Ordenado
paginas
descargado
paginas
Fundar
Enlaces
Hora
búsqueda
eficiencia
búsqueda
Enlaces
Nuevo
eficiencia
NuevoYandex 5 5 50 0:00:05 32% 0 0 5 5 44 0:00:03 28% 0 0 yahoo 5 5 50 0:00:05 32% 0 0 Excursionista 5 4 56 0:00:07 36% 0 0 MSN (Bing) 5 3 23 0:00:04 15% 0 0 Yandex.Blogs 5 1 1 0:00:01 1% 0 0 Google.Blogs 5 1 3 0:00:01 2% 0 0 Total: 35 24 227 0:00:26 — 0 0 - (! ) Repita su solicitud en unas horas o días, y verá en una lista separada solo nuevos enlaces , que apareció en la salida de Fuentes para este período de tiempo. En las dos últimas columnas de la tabla, puede ver cuántos enlaces nuevos trajo cada Fuente y su eficiencia en términos de "novedad". Cuando una consulta se ejecuta varias veces, una lista que contiene solo nuevos enlaces , se crea en relación con todas las ejecuciones anteriores de esta consulta. parecería elemental y función deseada, pero el autor no tiene conocimiento de ningún programa en el que esté implementado.
- (!! ) Las características descritas son compatibles no solo para solicitudes individuales, sino también para solicitudes completas. solicitar paquetes :
El paquete que ve consta de siete consultas diferentes que recopilan información sobre Vasily Shukshin de varias fuentes, incluidos los motores de búsqueda, Wikipedia, búsqueda exacta en las noticias de Yandex, metabúsqueda y búsqueda de menciones en estaciones de radio y televisión. al guion televisión y radio incluye: Channel One, TV Russia, NTV, RBC TV, Ekho Moskvy, la compañía de radio Mayak, ... y otras fuentes de información. Cada Fuente tiene su propia profundidad de búsqueda o visualización en las páginas. Se encuentra en la tercera columna.
La búsqueda por lotes permite una búsqueda completa con un solo clic colección de información sobre un tema dado.
Lista separada nuevos enlaces, en ejecuciones repetidas del paquete, contendrá solo referencias no encontradas antes.
Recuerda qué y cuándo le preguntaste a Internet y qué te respondió No hay necesidad- todo se guarda automáticamente en las bibliotecas y bases de datos del programa.
Reitero que las características descritas en este párrafo están totalmente incluidas en el paquete. SitioSpunik Pro.
Lea más en las instrucciones: SiteSputnik Pro para principiantes.
3. Objetos de búsqueda y seguimiento
Muy a menudo, el usuario se enfrenta a la siguiente tarea. Necesita averiguar qué hay en Internet sobre un objeto en particular: una persona o una empresa. Por ejemplo, al contratar a un nuevo empleado o cuando aparece una nueva contraparte, siempre sabes el nombre completo, razón social, números de teléfono, TIN, PSRN o PSRNIP, también puedes llevar ICQ, Skype y algunos otros datos. Además, usando la llamada a la función especial del programa SitioSputnik "Recopilación de información sobre el objeto." (equipo SiteSputnik Pro+Objetos):Introduces los datos que conoces, y con un clic del ratón, preciso y completo buscar enlaces que contengan la información dada. La búsqueda se realiza en varios motores de búsqueda a la vez, usando todos los detalles a la vez, usando varias combinaciones posibles de detalles a la vez: recuerde cómo puede escribir un número de teléfono de diferentes maneras. Después de un cierto período de tiempo, sin hacer un aburrido trabajo de rutina, recibirá una lista de enlaces, libres de repeticiones y, lo más importante, ordenados por relevancia para el objeto que está buscando. La relevancia (importancia) se logra debido a que los primeros en la emisión de SiteSputnik serán aquellos enlaces en los que el gran cantidad detalles especificados por usted, y no aquellos que promovieron los resultados del motor de búsqueda del Webmaster.
Importante .
El programa SiteSputnik es capaz de extraer mejor que otros programas verdadero, pero no oficial información sobre el Objeto. Por ejemplo, en la base de datos oficial operador móvil se puede escribir que el teléfono pertenece a Vasily Terekhin, pero en realidad este teléfono tiene información de que Alexander vendió un auto Ford Focus en 2013, que es información adicional para la reflexión.Monitoreo de búsqueda .
Seguimiento de búsqueda significa lo siguiente. Si desea realizar un seguimiento de la apariencia nuevos enlaces, por un objeto dado o arbitrario lote de solicitudes, solo necesita repetir periódicamente la búsqueda correspondiente. Así como para una simple solicitud, Programa SiteSputnik creará una lista "Nueva", en la que colocará únicamente aquellos enlaces que no se hayan encontrado en ninguna de las búsquedas anteriores.Monitoreo de búsqueda interesante no sólo en sí mismo. Puede estar involucrado en seguimiento de medios, redes sociales y otras fuentes de noticias, que se mencionó anteriormente en el párrafo 1. A diferencia de otros programas en los que es posible eliminar información nueva solo de fuentes RSS, el programa SitioSputnik se puede usar para esto búsquedas en el sitio y los motores de búsqueda . También es posible emulación(creación propia) varios RSS Feeds desde páginas arbitrarias, además, la emulación de un feed RSS en una solicitud e incluso un lote de solicitudes.
- Para aprovechar al máximo el programa, utilice sus características principales, a saber:
- solicitar paquetes, paquetes con parámetros, usar Assembler (colector), la operación de "Unión analítica" de los resultados de varias tareas, si es necesario, aplicar funciones de búsqueda básicas en la Internet invisible;
- conecte sus fuentes a las fuentes de información integradas en el programa : otros motores de búsqueda y búsquedas en el sitio, fuentes RSS existentes creadas por usted fuentes RSS propias Con arbitrario páginas, aplicar la búsqueda de nuevas fuentes;
- aprovecha las siguientes opciones supervisión: Medios de comunicación, redes sociales y otras fuentes, seguimiento comentarios a noticias y mensajes, rastrear la aparición de nueva información en páginas existentes;
- comprometerse Categorías , Funciones externas, Programador de tareas, Lista de correo, Múltiples computadoras, Instructor de proyectos, Instalar alarma para notificar sobre la ocurrencia de eventos significativos, use las otras funciones que se enumeran a continuación.
4. Programa SiteSputnik (SiteSputnik): opciones y caracteristicas
- Programa SitioSputnik mejorando constantemente en la dirección de: "Necesito encontrar todo y con garantia".
"Programa para interrogar a Internet", es otra definición del Usuario al que asignar el programa.UNA. Funciones de búsqueda y recogida de información.
. Solicitar paquete - ejecución de varias consultas a la vez con la combinación de resultados de búsqueda o por separado. Al generar un resultado combinado, los enlaces reencontrados se eliminan. Más sobre paquetes, en la introducción a SiteSputnik, visualmente, en el video: una articulación y separar ejecución de solicitudes. No hay análogos en los desarrollos nacionales y extranjeros.
. Paquetes con parámetros. Cualquier solicitud y paquete de solicitudes diseñado para resolver tareas de búsqueda estándar, por ejemplo, buscar por teléfono, nombre o Email, - se puede parametrizar, guardar y ejecutar desde una biblioteca de solicitudes preparadas con sustitución de los valores de parámetro reales (requeridos). Cada paquete con parámetros es especial. formulario de busqueda avanzada . Puede utilizar no uno, sino varios motores de búsqueda. Es posible crear formas que son muy complejas en su propósito funcional. Es extremadamente importante que formularios pueden ser creados por los propios usuarios, sin la participación del autor del programa o del programador. Es extremadamente simple sobre esto está escrito en las instrucciones, más detalles en una publicación separada sobre la parametrización de la búsqueda y en el foro, claramente en el video: busque todas las opciones de ingreso de números a la vez teléfono móvil y por varias opciones para escribir la dirección Correo electrónico. No hay análogos.
. ensamblador NUEVO- montaje de una tarea de búsqueda a partir de varios ready-made : solicitudes, paquetes de solicitud y paquetes de parámetros. Los paquetes pueden contener otros paquetes en su texto. La profundidad de anidamiento de paquetes es ilimitada. Puede crear varias tareas de búsqueda, por ejemplo, sobre varias personas físicas y jurídicas, y completar estas tareas al mismo tiempo. Más detalles en el foro y en una publicación separada sobre Assembler, claramente en video. No hay análogos.
. Metabúsqueda - ejecución de una consulta específica simultáneamente para una "profundidad" dada de la búsqueda para cada uno de ellos. La metabúsqueda es posible en motores de búsqueda integrados, que incluyen Yandex, Rambler, Google, Yahoo, MSN (Bing), Mail, Yandex y blogs de Google, y en herramientas de búsqueda conectadas. Trabajar con varios motores de búsqueda parece que está trabajando con un motor de búsqueda . Los enlaces vueltos a encontrar se eliminan. Metabúsqueda visual en tres redes sociales conectadas: VKontakte, Twitter y Youtube, se muestra en video.
. metabúsqueda del sitio - unificación de la búsqueda de sitios en Google, Yahoo, Yandex, MSN (Bing). claramente en video.
. Metabúsqueda en documentos de oficina - combinación de búsqueda en archivos PDF, XLS, DOC, RTF, PPT, FLASH en Google, Yahoo, Yandex, MSN (Bing). Puede elegir cualquier combinación de formatos de archivo.
. Copias de caché de metabúsqueda enlaces en Yandex, Google, Yahoo, MSN (Bing). Se compila una lista, en cada párrafo de la cual se recopilan todos los fragmentos encontrados para cada enlace por cada motor de búsqueda. No hay análogos.
. Búsqueda profunda para Yandex, Google y Rambler, le permite combinar en una lista todos los enlaces de la búsqueda regular y todos los enlaces, respectivamente, de "Más del sitio", "Resultados adicionales del sitio" y "Buscar en el sitio (Total ...)" listas. Lea más sobre la búsqueda profunda en el foro. No hay análogos.
. Búsqueda precisa y completa . Esto significa lo siguiente. Por un lado, cada consulta puede ejecutarse sobre esa y sólo esa fuente, en cuyo lenguaje de consulta está escrita. Esta búsqueda exacta. Por otro lado, puede haber un número arbitrario de dichas solicitudes y fuentes. Esto proporciona búsqueda completa. Más detalles en una publicación separada sobre búsqueda procesal. No hay análogos.
. Buscando en la Web Invisible .
Incluye las siguientes características básicas:
B. Funciones de seguimiento de la información.Un paquete especial de solicitudes que el Usuario puede mejorar,
- buscar enlaces invisibles usando una araña (araña),
- buscar enlaces invisibles en las proximidades de un enlace o carpeta visible por "imagen y semejanza",
- búsquedas especiales de carpetas abiertas,
- busque enlaces invisibles y carpetas con nombres estándar usando diccionarios especiales,
- uso de sus propias búsquedas integradas en los sitios.Más detalles en una publicación separada en SiteSputnik Invisible. Las funciones básicas son "bien conocidas en círculos estrechos", pero la forma en que se utilizan no tiene análogos. La esencia de este método es construir un mapa del sitio visible desde Internet (en otras palabras, la materialización de Internet visible), y solo sobre la base de enlaces visibles y, en relación con ellos, la búsqueda de enlaces invisibles. No se realiza la búsqueda de enlaces ya visibles por métodos "invisibles".
. Supervisión por aparecer en internet nuevo enlaces sobre un tema determinado. Apariencia del monitor nuevo los enlaces pueden estar usando todo solicitar paquetes , que involucran cualquiera de los métodos de búsqueda mencionados anteriormente, y no las primeras páginas individuales de los motores de búsqueda. Unión e intersección implementadas nuevo enlaces de varias búsquedas separadas. Más detalles en la publicación de seguimiento (ver § 1) y en el foro. No hay análogos.
. Procesamiento de información colectiva . Creación red corporativa o profesional para la recopilación, el seguimiento y el análisis colectivos de la información. Los participantes y creadores de dicha red son empleados de la corporación, miembros de la comunidad profesional o grupos de interés. No importa la ubicación geográfica de los participantes. Más detalles en una publicación separada sobre la organización de una red de recolección colectiva, monitoreo y análisis de información.
. Supervisión enlaces (páginas web) para detectar cambios en su contenido (contenido). Versión beta. Los cambios encontrados se resaltan con colores y signos especiales. Más detalles en una publicación de monitoreo separada (ver § 2 y 3).
v Funciones de análisis de la información.
. Categoría de materiales ya descrito anteriormente. Más detalles - en una publicación separada sobre Rúbricas. Las reglas de acierto de las rúbricas le permiten especificar palabras clave y la distancia entre ellas, establecer "Y", "O" y "NO" lógicos, aplicar una estructura de paréntesis de varios niveles y diccionarios (insertar archivos) a los que puede aplicar operaciones lógicas.
. tecnología VF - expansión casi arbitraria de la posibilidad de categorizar materiales mediante la implementación de funciones externas que están integradas orgánicamente en las Reglas para ingresar a las Rúbricas y pueden ser implementadas por el programador de forma independiente sin la participación del autor del programa.
. Análisis numérico Rúbricas de ocupación, instalación señalización y notificación de la ocurrencia de eventos significativos resaltando Rúbricas y/o enviando un reporte de alarma por e-mail.
. relevancia real. Hay una opción para organizar los enlaces en orden cerca de la importancia estos enlaces en relación con el problema que se está resolviendo, pasando por alto los trucos de los webmasters que utilizan varias maneras aumentar la clasificación de los sitios en los motores de búsqueda. Esto se logra analizando los resultados de varias consultas "diversas" sobre un tema determinado. Calculado, en el verdadero sentido de la palabra, enlaces que contienen información máxima requerida . Lea más en la descripción de cómo encontrar el mejor proveedor y en el foro. No hay análogos.
. Cálculo de relaciones de objetos - buscar enlaces, recursos (sitios), carpetas y dominios que mencionen objetos simultáneamente. Los objetos más comunes son las personas y las empresas. Para buscar conexiones, se pueden utilizar todas las herramientas del programa mencionadas en esta página. SitioSputnik lo que aumenta significativamente la eficiencia de su trabajo. La operación se realiza en cualquier número de objetos. Más detalles en la introducción al programa, así como en la descripción de la nueva característica "objetos y sus relaciones". No hay análogos.
. Formación, asociación e intersección de flujos de información sobre una variedad de temas, coincidencia de flujos. Más detalles en una publicación separada.
. Creación de mapas web sitios, recursos, carpetas y objetos buscados basados en los enlaces que se encuentran en Internet utilizando los enlaces de Google, Yahoo, Yandex, MSN (Bing) y Altavista que pertenecen al sitio. Los expertos pueden averiguar si puede ver "extra" información de Internet en sus sitios, así como investigar los sitios de competidores sobre este tema. El mapa del sitio web es materialización de la internet visible . Más detalles en una publicación separada sobre la creación de mapas web, claramente en video. No hay análogos.
. Búsqueda de nuevas fuentes de información. sobre un tema determinado, que luego se puede aplicar para rastrear la aparición de nueva información relevante. Lea mas en.
GRAMO. Funciones de servicio.
. Programador de tareas proporciona trabajo Programado: realiza las funciones especificadas del programa en el momento especificado. Lea más en una publicación separada sobre Scheduler.
. Instructor de proyectos NUEVO es un asistente creación y mantenimiento Proyectos de búsqueda, recolección, seguimiento y análisis de información (categorización y señalización). Leer más en el foro.
. Archivado automático. V bases de datos todos los resultados de su trabajo se almacenan automáticamente, a saber: solicitudes, paquetes de solicitud, protocolos de búsqueda y monitoreo, cualquier otra función mencionada anteriormente y los resultados de su ejecución. Poder estructura trabajar sobre temas y subtemas.
. Base de datos incluye clasificaciones, búsquedas simples y búsquedas arbitrarias por consulta SQL. Para este último, existe un asistente para la compilación de consultas SQL. Con estas herramientas, puede encontrar y familiarizarse con el trabajo que realizó ayer, el mes pasado, hace un año, definir un tema como criterio de búsqueda o establecer otro criterio de búsqueda para el contenido de la base de datos.
. Limitaciones técnicas los motores de búsqueda. Se pueden superar algunas restricciones, como la longitud de la cadena de consulta. Se proporciona la ejecución de no una, sino varias consultas con la combinación de resultados de búsqueda o por separado. Puede leer sobre la forma de superar la violación de la ley de aditividad para los principales motores de búsqueda. Para una palabra o una frase, entre comillas, se implementa una búsqueda que distingue mayúsculas de minúsculas en los motores de búsqueda, en particular, una búsqueda por abreviaturas.
incorporado navegador . Navegador por páginas. Multicolor marcador para resaltar palabras clave y arbitrarias. Bilisting y N-listing a partir de documentos generados.
. Descarga se alimenta en una vista tabular enfocada en importar en Excel, MySQL, Access, Kronos y otras Aplicaciones.
5. Instalación y ejecución del Programa, requisitos informáticos.
Para instalar y ejecutar el programa:
- Descargue el archivo, copie la carpeta FileForFiles de este a su disco duro, por ejemplo, en D:\;
- Versión demo del programa será instalado y se abrirá.
El programa funcionará en cualquier computadora que tenga Windows de cualquier versión instalada.La búsqueda profesional en Internet requiere software especializado, así como motores de búsqueda y servicios de búsqueda especializados.
PROGRAMAS
http://dr-watson.wix.com/home: un programa diseñado para estudiar matrices de información textual para identificar entidades y relaciones entre ellas. El resultado del trabajo es un informe sobre el objeto de estudio.
http://www.fmsasg.com/ - Sentinel Vizualizer es uno de los mejores software de visualización de conexiones y relaciones del mundo. La empresa rusificó completamente sus productos y los conectó línea directa en ruso.
http://www.newprosoft.com/ - "Web Content Extractor" es el software de extracción de datos de sitios web más poderoso y fácil de usar. También tiene una eficiente araña Visual Web.
SitioSputnik – un paquete de software que no tiene análogos en el mundo, que le permite buscar y procesar sus resultados en Internet Visible e Invisible, utilizando todos los motores de búsqueda necesarios para el usuario.
WebSite-Watcher: le permite monitorear páginas web, incluidas las protegidas con contraseña, monitorear foros, fuentes RSS, grupos de noticias, archivos locales. Tiene un potente sistema de filtrado. El monitoreo es automático y se entrega de una manera fácil de usar. El programa con funciones avanzadas cuesta 50 euros. Actualizado constantemente.
http://www.scribd.com/ es la plataforma más popular del mundo y cada vez más utilizada en Rusia para alojar varios tipos de documentos, libros, etc. de libre acceso con un muy cómodo buscador de nombres, temas, etc.
http://www.atlasti.com/ - es la herramienta más poderosa y efectiva disponible para usuarios individuales, pequeñas e incluso medianas empresas para el análisis de información cualitativa. El programa es multifuncional y por lo tanto útil. Combina las posibilidades de crear un entorno de información único para trabajar con varios archivos de texto, hoja de cálculo, audio y video en su conjunto, así como herramientas para el análisis cualitativo y la visualización.
Ashampoo ClipFinder HD: una proporción cada vez mayor del flujo de información es video. En consecuencia, los exploradores competitivos necesitan herramientas para trabajar con este formato. Uno de estos productos es el utilidad gratuita. Le permite buscar videos por criterios específicos en almacenamientos de archivos de video como YouTube. El programa es fácil de usar, muestra todos los resultados de búsqueda en una página con información detallada, títulos, duración, hora en que se cargó el video en el almacenamiento, etc. Hay una interfaz rusa.
http://www.advego.ru/plagiatus/ - el programa está hecho optimizadores seo, pero es bastante adecuado como herramienta de inteligencia de Internet. El plagio muestra el grado de singularidad del texto, las fuentes del texto, el porcentaje de coincidencia de texto. El programa también verifica la unicidad de la URL especificada. El programa es gratuito.
http://neiron.ru/toolbar/ - incluye un complemento para combinar búsqueda de Google y Yandex, y también permite un análisis competitivo basado en la evaluación de la efectividad de los sitios y la publicidad contextual. Implementado como complemento para FF y GC.
http://web-data-extractor.net/ es una solución universal para obtener cualquier dato disponible en Internet. La configuración de datos de corte desde cualquier página se realiza con unos pocos clics del mouse. Solo necesita seleccionar el área de datos que desea guardar y Datacol seleccionará la fórmula para cortar este bloque.
CaptureSaver es una herramienta profesional de investigación en Internet. Simplemente insustituible programa de trabajo, que le permite capturar, almacenar y exportar cualquier información en Internet, incluyendo no solo páginas web, blogs, pero también noticias RSS, correo electrónico, imágenes y más. Tiene la más amplia funcionalidad, una interfaz intuitiva y un precio irrisorio.
http://www.orbiscope.net/en/software.html - sistema de monitorización web a precios más que asequibles.
http://www.kbcrawl.co.uk/ - software para el trabajo, incluso en el "Internet invisible".
http://www.copernic.com/en/products/agent/index.html: el programa le permite buscar utilizando más de 90 motores de búsqueda, más de 10 parámetros. Le permite fusionar resultados, eliminar duplicados, bloquear enlaces rotos, mostrar los resultados más relevantes. Viene en versiones gratuitas, personales y profesionales. Utilizado por más de 20 millones de usuarios.
Maltego es un software fundamentalmente nuevo que le permite establecer la relación de sujetos, eventos y objetos en la vida real y en Internet.
SERVICIOS
new es un navegador web con docenas de herramientas preinstaladas para OSINT.
es un agregador de búsqueda efectivo para encontrar personas en las principales redes sociales rusas.
https://hunter.io/ es un servicio eficiente de detección y verificación de correo electrónico.
https://www.whatruns.com/ es un escáner fácil de usar pero efectivo para descubrir qué funciona y qué no funciona en un sitio web y cuáles son los agujeros de seguridad. También implementado como complemento para Chrom.
https://www.crayon.co/ es una plataforma estadounidense de inteligencia competitiva y mercado de bajo costo en Internet.
http://www.cs.cornell.edu/~bwong/octant/ - localizador de host.
https://iplogger.ru/: un servicio simple y conveniente para determinar la IP de otra persona.
http://linkurio.us/ es un producto nuevo y poderoso para trabajadores de seguridad económica e investigadores de corrupción. Procesa y visualiza grandes conjuntos de información no estructurada de fuentes financieras.
http://www.intelsuite.com/en es una plataforma en línea en inglés para inteligencia y monitoreo competitivo.
http://yewno.com/about/ es el primer sistema operativo para traducir información en conocimiento y visualizar información no estructurada. Actualmente es compatible con los idiomas inglés, francés, alemán, español y portugués.
https://start.avalancheonline.ru/landing/?next=%2F: servicios analíticos y de pronóstico de Andrey Masalovich.
https://www.outwit.com/products/hub/ - juego completo Programas offline para trabajo profesional en la web 1.
https://github.com/search?q=user%3Acmlh+maltego - extensiones para Maltego.
http://www.whoihostingthis.com/ - motor de búsqueda de hosting, direcciones IP, etc.
http://appfollow.ru/ - análisis de aplicaciones basado en reseñas, optimización ASO, posiciones en los tops y resultados de búsqueda para App Store, Google Play y Windows Phone Store.
http://spiraldb.com/ es un servicio implementado como un complemento para Chrom que le permite obtener mucha información valiosa sobre cualquier recurso electrónico.
https://millie.northernlight.com/dashboard.php?id=93 - un servicio gratuito que recopila y estructura información clave sobre industrias y empresas. Es posible utilizar paneles informativos basados en análisis de texto.
http://byratino.info/ - recopilación de datos fácticos de fuentes disponibles públicamente en Internet.
http://www.datafox.co/ - Plataforma de CI que recopila y analiza información sobre empresas de interés para los clientes. Hay una demostración.
https://unwiredlabs.com/home: una aplicación especializada con una API para buscar por geolocalización de cualquier dispositivo conectado a Internet.
http://visualping.io/ es un servicio para monitorear sitios y, en primer lugar, las fotos e imágenes en ellos. Incluso si la foto apareció por un segundo, estará en Email abonado. Tiene un plugin para Google Chrome.
http://spyonweb.com/ es una herramienta de investigación que le permite análisis en profundidad cualquier recurso de Internet.
http://bigvisor.ru/: el servicio le permite rastrear campañas publicitarias para ciertos segmentos de bienes y servicios, o para organizaciones específicas.
http://www.itsec.pro/2013/09/microsoft-word.html - Instrucciones de Artem Ageev sobre el uso de programas de Windows para las necesidades de inteligencia competitiva.
http://granoproject.org/ es una herramienta de código abierto para investigadores que rastrean redes de conexiones entre personas y organizaciones en política, economía, crimen y más. Permite conectar, analizar y visualizar información obtenida de diversas fuentes, así como mostrar relaciones significativas.
http://imgops.com/ es un servicio para extraer metadatos de archivos gráficos y trabajar con ellos.
http://sergeybelove.ru/tools/one-button-scan/ - un pequeño escáner en línea para comprobar agujeros de seguridad en sitios web y otros recursos.
http://isce-library.net/epi.aspx - servicio de búsqueda de fuentes primarias por fragmento de texto en inglés
https://www.rivaliq.com/ es una herramienta eficaz para realizar inteligencia competitiva en los mercados occidentales, principalmente europeos y estadounidenses, de bienes y servicios.
http://watchthatpage.com/ es un servicio que le permite recopilar automáticamente nueva información de recursos monitoreados en Internet. Los servicios de servicio son gratuitos.
http://falcon.io/ es una especie de Informe para la Web. No reemplaza a Rapportive, pero proporciona herramientas adicionales. A diferencia de Rapportive, brinda un perfil general de una persona, como si estuviera pegado a partir de datos de redes sociales y menciones en web.http://watchthatpage.com/, un servicio que le permite recopilar automáticamente nueva información de recursos monitoreados en la Internet. Los servicios de servicio son gratuitos.
https://addons.mozilla.org/en/firefox/addon/update-scanner/ es un complemento para Firefox. Realiza un seguimiento de las actualizaciones de la página web. Útil para sitios web que no tienen feeds de noticias (Atom o RSS).
http://agregator.pro/ es un agregador de portales de noticias y medios. Utilizado por especialistas en marketing, analistas, etc. para analizar los flujos de noticias sobre determinados temas.
http://price.apishops.com/ es un servicio web automatizado para monitorear los precios de grupos de productos seleccionados, tiendas en línea específicas y otros parámetros.
http://www.la0.ru/ es un servicio conveniente y relevante para analizar enlaces y backlinks a un recurso de Internet.
www.recordedfuture.com es una poderosa herramienta de análisis y visualización de datos implementada como un servicio en línea basado en computación en la nube.
http://advse.ru/ es un servicio bajo el lema "Aprenda todo sobre sus competidores". Le permite obtener los sitios web de la competencia de acuerdo con las consultas de búsqueda, analizar las campañas publicitarias de la competencia en Google y Yandex.
http://spyonweb.com/: el servicio le permite identificar sitios con las mismas características, incluidos aquellos que utilizan los mismos identificadores del servicio de estadísticas de Google Analytics, direcciones IP, etc.
http://www.connotate.com/solutions: una línea de productos para la inteligencia competitiva, la gestión del flujo de información y la transformación de la información en activos de información. Incluye plataformas complejas y servicios simples y económicos que le permiten monitorear de manera efectiva junto con la compresión de información y obtener solo los resultados que necesita.
http://www.clearci.com/ es una plataforma de inteligencia competitiva para empresas de todos los tamaños, desde nuevas empresas y pequeñas empresas hasta empresas Fortune 500. Diseñado como saaS.
http://startingpage.com/ es un complemento de Google que le permite buscar en Google sin fijar su dirección IP. Totalmente compatible con todos los motores de búsqueda Funciones de Google, incluso en ruso.
http://newspapermap.com/ es un servicio único que es muy útil para un oficial de inteligencia competitiva. Conecta la geolocalización con un motor de búsqueda de medios en línea. Aquellos. usted elige la región o incluso la ciudad o el idioma que le interesa, ve el lugar y la lista de versiones en línea de periódicos y revistas en el mapa, hace clic en el botón correspondiente y lee. Admite el idioma ruso, una interfaz muy fácil de usar.
http://infostream.com.ua/ es un sistema de monitoreo de noticias de Infostream muy conveniente, que se distingue por una selección de primera clase, bastante asequible para cualquier billetera, de uno de los clásicos de búsqueda en Internet D.V. Lande.
http://www.instapaper.com/ es una herramienta muy sencilla y eficaz para guardar las páginas web necesarias. Se puede usar en computadoras, iPhones, iPads, etc.
http://screen-scraper.com/: le permite extraer automáticamente toda la información de las páginas web, descargar la gran mayoría de los formatos de archivo, ingresar datos automáticamente en varios formularios. Los archivos y páginas descargados se almacenan en bases de datos y realizan muchas otras funciones extremadamente útiles. Funciona en todas las plataformas principales, tiene versiones profesionales gratuitas y muy potentes totalmente funcionales.
http://www.mozenda.com/ - con varios planes de tarifas y accesible incluso para pequeñas empresas, un servicio web para monitoreo web multifuncional y entrega de información necesaria para el usuario desde sitios seleccionados.
http://www.recipdonor.com/: el servicio le permite monitorear automáticamente todo lo que sucede en los sitios de los competidores.
http://www.spyfu.com/ - y esto es si tiene competidores extranjeros.
www.webground.su es un servicio de monitoreo de Runet, creado por profesionales de búsqueda en Internet, que incluye a todos los principales proveedores de información, noticias, etc., y es capaz de configuraciones de monitoreo individuales para las necesidades del usuario.
LOS MOTORES DE BÚSQUEDA
https://www .idmarch .org/ es el mejor motor de búsqueda del archivo mundial de documentos pdf en términos de calidad. Actualmente, se han indexado más de 18 millones de documentos pdf, que van desde libros hasta informes clasificados.
http://www.marketvisual.com/ es un motor de búsqueda único que le permite buscar propietarios y altos directivos por nombre completo, nombre de la empresa, puesto o una combinación de ellos. V Resultados de la búsqueda contiene no sólo los objetos deseados, sino también sus relaciones. Diseñado principalmente para países de habla inglesa.
http://worldc.am/ es un buscador de fotografías de libre acceso con referencia a la geolocalización.
https://app.echosec.net/ es un motor de búsqueda de dominio público que se describe a sí mismo como la herramienta de análisis más avanzada para los profesionales de las fuerzas del orden y la seguridad y la inteligencia. Le permite buscar fotos publicadas en varios sitios, plataformas sociales y en redes sociales en relación a coordenadas de geolocalización específicas. Actualmente hay siete fuentes de datos conectadas. Para fin de año, su número será más de 450. Gracias a Dementy por la sugerencia.
http://www.quandl.com/ es un motor de búsqueda de siete millones de bases de datos financieras, económicas y sociales.
http://bitzakaz.ru/ - motor de búsqueda de licitaciones y órdenes gubernamentales con funciones pagas adicionales
Buscador de sitios web: permite encontrar sitios que están mal indexados por Google. La única limitación es que solo busca en 30 sitios web para cada palabra clave. El programa es fácil de usar.
http://www.dtsearch.com/ es el motor de búsqueda más poderoso que le permite procesar terabytes de texto. Funciona en escritorio, web e intranet. Admite datos estáticos y dinámicos. Le permite buscar en todos los programas de MS Office. La búsqueda se realiza por frases, palabras, etiquetas, índices y mucho más. El único motor de búsqueda federado disponible. Tiene versiones de pago y gratuitas.
http://www.strategator.com/: busca, filtra y agrega información de empresas de decenas de miles de fuentes web. Busca los EE.UU., Gran Bretaña, los principales países de la CEE. Es muy relevante, fácil de usar, tiene opciones gratuitas y pagas ($ 14 por mes).
http://www.shodanhq.com/ es un motor de búsqueda inusual. Inmediatamente después de la aparición, recibió el apodo de "Google para hackers". No busca páginas, pero determina direcciones IP, tipos de enrutadores, computadoras, servidores y estaciones de trabajo ubicadas en una dirección particular, rastrea cadenas servidores DNS y te permite implementar muchas otras características interesantes para la inteligencia competitiva.
http://search.usa.gov/ es un motor de búsqueda de sitios web y bases de datos abiertas de todas las agencias gubernamentales de EE. UU. Las bases de datos contienen mucha información práctica útil, incluso para uso en nuestro país.
http://visual.ly/ – La visualización se utiliza cada vez más para presentar datos. Es el primer motor de búsqueda infográfico en la web. Junto con el buscador, el portal cuenta con potentes herramientas de visualización de datos que no requieren conocimientos de programación.
http://go.mail.ru/realtime: busque debates sobre temas, eventos, objetos, asuntos en tiempo real o personalizado. La búsqueda anteriormente muy criticada en Mail.ru funciona de manera muy eficiente y brinda resultados interesantes y relevantes.
Zanran es el primer y único motor de búsqueda de datos que extrae datos de archivos PDF, tablas EXCEL, datos en páginas HTML.
http://www.ciradar.com/Competitive-Analysis.aspx es uno de los mejores motores de búsqueda del mundo para inteligencia competitiva en la web profunda. Extrae casi todo tipo de archivos en todos los formatos sobre el tema de interés. Implementado como un servicio web. Los precios son más que razonables.
http://public.ru/ - Búsqueda efectiva y análisis profesional de información, archivo de medios desde 1990. La biblioteca de medios en línea ofrece una amplia gama de servicios de información: desde acceso a archivos electrónicos de publicaciones de medios en idioma ruso y revistas de prensa temáticas listas para usar hasta monitoreo individual y estudios analíticos exclusivos basados en materiales de prensa.
Cluuz es un motor de búsqueda joven con amplias oportunidades para la inteligencia competitiva, especialmente en Internet de habla inglesa. Permite no solo encontrar, sino también visualizar, establecer vínculos entre personas, empresas, dominios, correos electrónicos, direcciones, etc.
www.wolframalpha.com es el motor de búsqueda del mañana. Para una consulta de búsqueda, emite información estadística y fáctica disponible en el objeto de la solicitud, incluida la información visualizada.
www.ist-budget.ru - búsqueda universal en bases de datos de contratación pública, licitaciones, subastas, etc.
Decir que en nuestra época de tecnología de la información y el crecimiento sin fin de la cantidad de datos disponibles tanto para una persona individual como para la sociedad, hay muchos problemas con el procesamiento de la información y su búsqueda ya es una blasfemia. Quien solo no plantea este tema. Y para no cargarlos con juicios subjetivos y, en parte, objetivos extraídos de diversas fuentes de información sobre el problema, procederé directamente a su solución. Hablemos de búsqueda hoy. Es decir, de programas y sistemas de información serios que buscan los documentos y datos que necesitamos.
Actualizar "búsqueda directa"
No hace mucho tiempo, cuando los árboles eran grandes y la información incluso en red local no había tantas empresas, cualquier búsqueda se realizaba mediante una enumeración banal de un puñado de archivos disponibles y una verificación constante de sus nombres y contenidos. Tal búsqueda se llama directa, y los programas (utilidades) que usan tecnología de búsqueda directa están tradicionalmente presentes en todos los sistemas operativos y paquetes de herramientas. Pero, incluso el poder de las computadoras modernas no es suficiente para una búsqueda rápida y adecuada en cantidades gigantescas de datos durante la búsqueda directa. Buscar en un par de cientos de documentos en un disco y buscar en una biblioteca enorme y varias docenas de buzones son dos cosas diferentes. Por lo tanto, los programas de búsqueda directa de hoy en día se están desvaneciendo claramente, si hablamos de herramientas universales.
Por supuesto, en el sector corporativo, este tipo de búsqueda no ha tenido demanda durante mucho tiempo. Los volúmenes no son los mismos. Y, por ello, desde hace ya muchos años, y últimamente inequívocamente, las tecnologías capaces de realizar una búsqueda rápida y precisa de documentos de varios formatos y de varias fuentes son más que relevantes. No hace mucho tiempo, el "padre" de Microsoft, Bill Gates, envidiando, aparentemente, el fenomenal éxito del motor de búsqueda de Internet de Google, en una de las conferencias de prensa anunció el deseo del software (ya y no solo) de todas las formas posibles para promover , desarrollar y profundizar en la creación de motores de búsqueda y tecnologías. Pero antes de la creación de cualquier programa de trabajo fenomenal de Microsoft o un servidor competitivo en Internet, todavía es demasiado pronto (MSN todavía está por debajo de Google). Por lo tanto, nos dirigimos a los desarrollos existentes. Índice, consulta, relevancia
En el núcleo tecnologías modernas hay dos procesos fundamentales. En primer lugar, es la indexación de la información disponible y el procesamiento de la solicitud, seguida de la salida de los resultados. En cuanto a lo primero, cualquier programa (ya sea un motor de búsqueda de escritorio, una empresa Sistema de informacion o motor de búsqueda de Internet) crea su propia área de búsqueda. Es decir, procesa documentos y forma un índice de estos documentos (una estructura organizada que contiene información sobre los datos procesados). En el futuro, es el índice creado el que se utiliza para el trabajo, obteniendo rápidamente una lista de los documentos necesarios de acuerdo con la solicitud. Además, aunque de ninguna manera es simple en términos de tecnología, es bastante comprensible para el usuario promedio. El programa procesa la solicitud (por frase clave) y muestra una lista de documentos que contienen esta frase clave. Dado que la información está contenida en un índice estructurado, el procesamiento de la consulta es mucho (¡decenas y cientos de veces!) más rápido que en el caso de una búsqueda directa (la selección de documentos no se realiza enumerando archivos, sino analizando la información textual en el índice).
El programa muestra los documentos encontrados en la lista resultante según su relevancia: la correspondencia del documento con el texto de la consulta. En varias tecnologías, por supuesto, hay varios métodos buscar y determinar la relevancia del documento (el número de "apariciones" de la palabra y su frecuencia de mención en el documento, la relación de estos parámetros con el número total de palabras en el documento, la distancia entre las palabras de la consulta frase en los archivos buscados, etc.). En función de estos parámetros, se determina el "peso" del documento y, dependiendo de él, aparece uno u otro archivo en la lista de resultados en una posición determinada. En el caso de la búsqueda en Internet, la situación es aún más complicada. Efectivamente, en este caso, hay que tener en cuenta muchos otros factores (el Page Rank de Google es un ejemplo de ello). Pero este es un tema para un artículo aparte, por lo que no tocaremos Internet.
V este material Se consideran las posibilidades de varios programas de búsqueda populares que cuentan con velocidades decentes y buena funcionalidad. Pero lucirse en un volante es una cosa, pero enfrentarse a la mirada de un experto es otra muy distinta. Y no hubo ni muchos ni pocos expertos, un despacho repleto de amantes a trastear con el software para su usabilidad. En una computadora de prueba (Athlon 2.2 MHz, 1 GB RAM, 160 GB IDE disco duro Seagate a 7200 rpm y sistema Windows XP) se instaló un conjunto de programas: dtSearch Desktop, Snoop Prof Deluxe, Google Desktop Search, SearchInform, Copernic Desktop Search, ISYS Desktop. Para las pruebas, se compiló una base de texto de documentos en formatos de documentos, txt y html con un tamaño total de nada más y nada menos que 20 gigas. Un grupo de camaradas, bajo la guía de su humilde servidor, probaron, compararon y compartieron sus impresiones subjetivas sobre cada software. Lea a continuación un resumen de los hallazgos. dtSearchDesktop
Un programa que, según los desarrolladores, pretende ser el más rápido, cómodo y mejor buscador. Como, en general, y todo el resto de esta revisión. La interfaz de dtSearch es bastante sencilla, pero algunas ventanas o pestañas están algo sobrecargadas de elementos, lo que da la impresión de ser difícil de usar. Pero, de hecho, no hay dificultades especiales. El único momento realmente desagradable es la falta de soporte para el software en idioma ruso (a pesar de que el programa puede buscar documentos en varios idiomas, su interfaz es exclusivamente en inglés).
Pero dtSearch es uno de los pocos programas que pueden indexar páginas web a una "profundidad" especificada por el usuario (sin embargo, teniendo en cuenta la "compra adicional" en el kit adicional de dtSearch Spider). Esto es además de admitir archivos en disco en varios formatos de texto y correos electrónicos desde buzón panorama. Al mismo tiempo, el programa no sabe trabajar con bases de datos, que son un bocado tan sabroso para los buscadores por la gran cantidad de información que contienen y la amplia distribución en las empresas, y por tanto en las redes corporativas. La velocidad de indexación de los documentos de dtSearch estuvo a la altura. De cara al futuro, diré que este programa hizo frente a la indexación de una determinada cantidad de información al mismo nivel que otro concursante, iSYS, y compartió con él el segundo lugar en la lista de los sistemas más rápidos. dtSearch indexó la prueba 20 gigabytes de información en 6 horas y 13 minutos, creando un índice de 7,9 GB de tamaño para las necesidades de búsqueda posterior.
En cuanto a las capacidades de búsqueda, aquí están a la altura. Primero, dtSearch tiene una búsqueda morfológica (búsqueda de una palabra en todas sus formas morfológicas). Utilizando esta oportunidad, se libera de, por ejemplo, pensamientos como "¿en qué caso se usó cierta palabra en el documento que necesitaba?". El uso de la búsqueda morfológica casi siempre está justificado, por lo que debería estar presente en cualquier buscador profesional.
La búsqueda por sonido es una característica no estándar incluso para los motores de búsqueda profesionales. Su esencia radica en el hecho de que el programa buscará palabras que suenen igual que la palabra que ingresó. ¡Y la mejor parte es que esta característica también funciona para el idioma ruso! Por ejemplo, escribir la palabra "oreja" en una consulta de búsqueda dará como resultado no solo las palabras "oreja", sino también "oreja".
La búsqueda de corrección de errores es una característica muy importante. Se utiliza para buscar palabras que contienen errores sintácticos; estos pueden ser errores tipográficos o errores en documentos obtenidos mediante sistemas de reconocimiento de caracteres, por ejemplo. Un ejemplo simple es que está buscando la palabra teclado. Algún documento contiene la palabra "teclado", es obvio que en realidad esta palabra es "teclado", solo una persona escribiendo mientras escribe. Ahora, la búsqueda de corrección de errores detectará e incluirá el documento con la palabra "teclado" en el resultado. También en dtSearch hay una configuración que le permite determinar el grado de posibles caracteres erróneos.
Buscar usando sinónimos. Esta característica utiliza una lista de sinónimos para varias palabras. Entonces, por ejemplo, al ingresar la palabra "rápido", el programa también encontrará las palabras "alta velocidad" y otras que son sinónimos de la palabra "rápido", si las hay, por supuesto, están presentes en la lista de sinónimos . El programa dtSearch no incluye una lista preparada de sinónimos; sin embargo, es posible usar las listas en Internet (en consecuencia, se requiere una conexión, lo que no siempre es conveniente), o puede crear su propia lista de sinónimos
Además de las funciones enumeradas, dtSearch puede buscar usando frases que consisten en palabras conectadas por operaciones lógicas. A cada palabra de la consulta se le puede asignar su propio "peso", es decir, significado. Una opción útil es usar un diccionario que consiste en no palabras significativas Sin embargo, para no tenerlos en cuenta al buscar, este diccionario también está vacío y tendrá que llenarlo usted mismo.
A continuación, considere las posibilidades del programa al trabajar en la red. De hecho, dtSearch no ofrece ninguna capacidad de red específica. Sin embargo, es bastante posible usarlo en la red. Alternativamente, puede crear algún índice y colocarlo en una carpeta pública (compartida). El programa en sí se puede instalar para cada usuario en una computadora, o ponerlo también en una carpeta abierta para Acceso público, y cree accesos directos de una manera especial para cada usuario por separado, utilizando parámetros de línea de comando, cuyo propósito se describe en el archivo de ayuda suministrado con el programa. Asimismo, existe la posibilidad instalación automática programas a la red utilizando un archivo MSI. Esto tendrá en cuenta la configuración de cada usuario conectado.
En general, un buen programa de la categoría de motores de búsqueda profesionales. Puede calificar para una buena calificación, sin embargo, ganarse la confianza y el respeto de los usuarios puede ser difícil para dtSearch debido a varios factores (no todo es fluido con la interfaz, los usuarios rusos están privados, no hay funciones brillantes para trabajar con la red) . En cuanto a la búsqueda de documentos directamente, el programa no tenía superposiciones con texto en ruso. Como no los había con la morfología declarada, ni con búsqueda difusa. El sistema encontró bastante adecuadamente documentos requeridos y por una simple petición en una palabra y por uso como Frase clave un par de párrafos, cualquier documento.
Sitio oficial:
Tamaño de distribución: 23 MbSnoop Prof DeluxeSegún el nombre, puede adivinar que hay soporte para el idioma ruso en este programa. Ya es agradable. En cuanto a la interfaz, en general, es algo inusual, pero muy atractiva en apariencia. Otra cosa es la comodidad. Un criterio muy controvertido, pero aún así, probablemente, una solución de múltiples ventanas no sea la mejor opción (la solicitud se ingresa en una ventana, el resultado se muestra en otra, etc.).
Bloodhound todavía usa los mismos índices para realizar búsquedas rápidas, pero la indexación es mucho más lenta que otros programas. Esto es muy extraño, especialmente considerando que las capacidades de procesamiento consultas de búsqueda tiene muy débiles, lo que significa que la estructura del índice no es complicada. Lo más probable es que el punto aquí esté en los algoritmos no optimizados. Este programa resultó ser un claro outsider de las velocidades de indexación y búsqueda: el tiempo empleado en crear un índice es seis veces mayor que el del mismo dtSearch e iSYS. Indexar 20 gigabytes de textos para un sabueso resultó en 38 horas y 46 minutos de trabajo. Y el "área de búsqueda" creada ocupaba el mismo tamaño en el disco duro que los datos originales con un pequeño menos: 19 gigabytes.
El Bloodhound puede presentarse como una alternativa al buscador estándar en Windows, difícilmente es capaz de más. El hecho de que la tarea principal del Buscador, la búsqueda más simple de archivos, esté indicada no solo por una pequeña cantidad de funciones para analizar el texto de las consultas de búsqueda y una búsqueda avanzada por atributos de archivo, sino incluso por una ventana de resultados que brinda enlaces directos a los archivos encontrados, así como a las carpetas que contienen estos archivos. La ventana de resultados no es muy informativa en el sentido de que puede leer todo el archivo encontrado solo ejecutándolo, es decir, no tiene un visor de archivos incorporado. Pero se proporciona un extracto del archivo, donde se encontró la palabra buscada, en general, este esquema de visualización recuerda mucho a los motores de búsqueda de Internet.
Hablando de las posibilidades específicas para procesar consultas de búsqueda, vale la pena señalar que no existe tal cosa como "buscar texto", lo máximo que se puede buscar es una frase, aunque solo sea porque no hay un campo de entrada de texto de varias líneas. Sin embargo, puede analizar la frase ingresada, y el Bloodhound nos ofrece aquí un conjunto de búsqueda estándar: operaciones lógicas, búsqueda por máscara y búsqueda de comillas ... no mucho. Hay algunos rudimentos de búsqueda morfológica en el programa, pero probablemente tan crudos que interfieren con el trabajo correcto (durante las pruebas, se notaron muchas superposiciones con un uso incorrecto de la morfología).
Pero el programa le permite especificar los atributos del archivo (fecha del documento, nombre del archivo, nombre de la carpeta) al buscar, y en estas consultas también puede usar el mismo conjunto de búsqueda. Además, puede buscar mensajes especificando los parámetros (De, Asunto... etc.).
Entonces, descubrimos la búsqueda en sí, ¿qué más tiene de interesante el programa, por el cual recibió tantos premios, según la información del sitio web oficial? Es difícil decir qué tiene de especial, lo más probable es que la interfaz de Bloodhound sea favorable a sí misma (solo exteriormente, sin mencionar la facilidad de uso).
Las operaciones con índices son muy estándar, lo bueno es la capacidad de actualizar los índices de forma programada. Además, los índices también se pueden utilizar en línea. A partir de ahora, tenemos que ser más específicos.
A pesar de lo primitivo de las consultas de búsqueda, el programa se puede utilizar para buscar archivos, por lo que se puede justificar su uso en redes. Aunque un tramo, ya que gran red la prioridad es buscar rápidamente datos mediante consultas de búsqueda complejas debido a la gran cantidad de información, y claramente hay problemas con la velocidad de la búsqueda y el programa. Debo decir que el trabajo con la red en Bloodhound está pensado como debería. Una aplicación separada está diseñada específicamente para esto: Bloodhound Server. Funciona de la misma manera que Bloodhound (tienen un motor de búsqueda), solo para documentos alojados en un servidor central o en recursos compartidos en una red corporativa. Bloodhound Server crea nuevos índices en recursos compartidos o utiliza los creados previamente. Cualquier usuario de la red corporativa puede conectarse al Servidor Bloodhound y utilizarlo para acceder a cualquier documento (ubicado en el índice actual) mediante un navegador de Internet. De acuerdo, este esquema es extremadamente conveniente: resulta que los archivos en su propia red se pueden buscar de la misma manera que la información en Internet a través de, por ejemplo, Google.
Al evaluar todas las ventajas y desventajas de este programa, la conclusión sugiere que sus capacidades probablemente no serán suficientes para las redes corporativas (a pesar de la buena organización del trabajo con la red), pero para una computadora doméstica o incluso para red domestica Ella realmente puede encajar. Aunque ni la rapidez del trabajo, ni las capacidades de búsqueda inspiran optimismo...
Sitio oficial en ruso:
Tamaño de distribución: 6 MbGoogle Desktop Search + GDS EnterprisePor supuesto, no podíamos ignorar a un desarrollador tan eminente. El nombre Google ya lo dice todo. Las personas que llevan años utilizando el buscador más potente de Internet probablemente se decidan a instalar este particular buscador en su ordenador sin duda alguna. Es como pensar: ¡Google en la computadora de tu casa! Sin embargo, sin sucumbir a las provocaciones con una marca ampliamente promocionada, intentemos considerar con seriedad y, lo que es más importante, objetividad, las posibilidades del motor de búsqueda "de escritorio" de Google.
Lo primero que llama la atención es la falta de un shell propio para el programa. Google Desktop Search todavía está en la ventana del navegador, respectivamente, toda la interfaz de la versión de escritorio se dirigió al software del hermano mayor de Internet. Si esto es bueno o malo es un punto discutible: a alguien le gusta el minimalismo en el diseño de este motor de búsqueda, y alguien quiere ver una aplicación completa llena de todo tipo de botones, etc.
¿Qué te llama la atención justo después del diseño? Y el hecho de que este mismo Google Desktop Search comience a indexar todo en la computadora, ¡sin ninguna demanda! Y lo que es más interesante, es imposible elegir rutas de indexación utilizando Google Desktop Search. Deberá descargar un programa separado (TweakGDS), que le permitirá expandirse ligeramente configuración de google Escritorio, incluida la especificación de los lugares necesarios para la indexación. Aunque, mientras lo resuelve todo, ya indexará el disco duro estándar, por lo que esta configuración es más necesaria cuando se trabaja con grandes cantidades de datos, lo cual es muy importante cuando se usa en redes corporativas (versión Enterprise). Sin embargo, no es un hecho que después de descargar TweakGDS, sus problemas se resolverán. Después de todo, necesita Microsoft. NET Framework y Microsoft Scripting Runtime. Sí... la instalación, así como el acceso a la configuración, podría haberse hecho más fácil, aunque, probablemente, los desarrolladores pueden entender: ¿por qué escribir algo nuevo cuando ya existe un motor de búsqueda listo para usar? computadora local y deje que el usuario "disfrute", y deje que el conocido nombre haga otra obra maestra de "esto". Vamos, terminemos esta digresión lírica y pasemos a la búsqueda.
En cuanto al análisis de consultas de búsqueda y la emisión de resultados, aquí todo es absolutamente idéntico a Google en Internet: el mismo sistema para mostrar resultados, el mismo conjunto estándar de operaciones lógicas para consultas de búsqueda. En general, Google Desktop Search, al igual que el programa anterior, está diseñado exclusivamente para buscar archivos; por supuesto, no hay un visor interno para estos archivos. La cantidad de formatos de archivo admitidos por Google Desktop Search es bastante suficiente, y también es bueno que busque en las páginas de Internet visitadas, tomando datos del caché. Las velocidades de búsqueda e indexación son bastante aceptables. Es cierto, para uso doméstico. Con unos impresionantes 20 gigabytes de textos, Google Desktop Search se gestionó en 8 horas y 17 minutos. Pasar unos días procesando información de la red corporativa de una gran empresa no sonríe a ningún administrador de sistemas. En el lado positivo: el tamaño del índice creado resultó estar al nivel (4,5 GB) con otro motor de búsqueda probado en esta revisión: SearchInform.
Una gran ventaja (u omisión, usted decide) de Google Desktop Search es que admite complementos que pueden mejorar mucho. Otra cosa es que conectar complementos y configurarlos complique tanto la tarea de instalar un buscador que empieces a preguntarte si todo esto es necesario cuando puedes instalar un programa normal y completo en el que ya estará todo presente. Después de todo, para usar cada función, deberá instalar nuevo complemento. Incluso para que el programa funcione completamente con archivos, se necesita una loción por separado. Fascina y seduce la gratuidad de todos estos módulos adicionales. Sin embargo, si no tiene en cuenta la versión de escritorio del motor de búsqueda, es posible que configurar GDS Enterprise de manera competente no esté dentro de su alcance; no es en vano que los especialistas de Google ofrezcan sus servicios para configurar los suyos. software para su red por solo $10,000.
Sin embargo, si domina el procedimiento de configuración e instalación (o paga $ 10,000 al equipo de respuesta rápida de Google), comprenderá que la complejidad de la instalación está más que compensada por configuraciones muy flexibles cuando se usa en redes corporativas. un punto importante el trabajo de google Escritorio en una red corporativa es el uso de políticas de grupo, lo que hace posible establecer preferencias para cada usuario.
Resumiendo, cabe decir que el uso más razonable de este programa es un ordenador de casa o del trabajo. De hecho, para una computadora normal, basta con instalar el programa: hará el resto por sí mismo (ni siquiera le preguntará nada).
Sin embargo, Google Desktop Search Enterprise será aceptable en los casos en que exista una necesidad urgente de una configuración de política de red flexible para usar el motor de búsqueda, mientras que la capacidad de procesar consultas de búsqueda estará en segundo lugar en importancia y el tiempo (o dinero) gastado en configurar el programa ocupará el primer lugar.
Sitio oficial:
Tamaño de distribución con TweakGDS: 1.2 MbCopernic Desktop SearchHaga clic en la foto para ampliarla
La interfaz del programa evoca emociones extremadamente positivas: todo se hace de acuerdo con los estándares generalmente aceptados, nada superfluo, en una palabra, un diseño agradable. Será muy fácil para un principiante comprender la interfaz de Copernic Desktop Search. Aunque es un poco vergonzoso que los diseñadores hayan creado explícitamente la interfaz del programa, teniendo en cuenta el hecho de que el programa funcionará en un tema estándar. diseño de ventanas xp. Al usar el mismo tema clásico, el programa no se ve tan bonito. Pero esto es más una cuestión de gustos.
Al principio, el programa ofrece crear índices para la búsqueda. Parecía algo inusual que después de seleccionar carpetas para indexar, el programa no ofrece presionar ningún botón, como "Iniciar indexación", mientras que la indexación no se inicia automáticamente, solo entonces se notó que Copernic intenta comenzar a indexar cuando la computadora está inactiva . Tendrás que indagar un poco en las opciones del programa para configurarlo todo correctamente. Cabe señalar que hay opciones bastante amplias para la personalización. creación automáticaíndice: programador incorporado, la capacidad de indexar mientras la computadora está inactiva, en segundo plano, con baja prioridad. La indexación no fue demasiado rápida, 10 horas y 51 minutos, es más lenta que en otros motores de búsqueda (a excepción de Bloodhound, pero Copernic es un orden de magnitud más rápido que el desarrollo de iSleuthHound Technologies.
Ahora sobre la estructura del índice. En general, no tiene nada de especial. Es posible seleccionar tipos de archivos, tanto de forma generalizada como detallada. Es decir, inicialmente puede elegir lo que desea indexar: Documentos, Imágenes, Videos, Música. En la otra pestaña de la ventana de opciones, será posible seleccionar tipos de archivos específicos por extensión. Además, puede configurar el índice de tal manera que, por ejemplo, las imágenes de menos de 16x16 de tamaño no se indexen o los archivos de sonido de menos de 10 segundos de duración no se indexen. Además de indexar archivos de carpetas, Copernic puede trabajar con correos electrónicos y contactos de la libreta de direcciones de Microsoft Outlook y Microsoft Outlook Express, es posible indexar Favoritos e Historial de Internet Explorer.
En cuanto a las capacidades de búsqueda, aquí son muy débiles. Durante las pruebas, incluso se reveló que el programa no busca documentos en formato txt y html en ruso, lo que le permite encontrarlos solo por encabezados y de ninguna manera por contenido. Lo único que proporciona el programa para mejorar la eficiencia de la búsqueda es el uso de un conjunto estándar de operaciones lógicas, e incluso entonces, esta característica se descubrió de forma experimental, ya que no estaba documentada. Por cierto, la ayuda del programa tampoco está bien: solo está disponible a través de Internet, lo que, como puede ver, es muy inconveniente, y no hay demasiada información de ayuda en la red. Aparentemente, los desarrolladores decidieron que la interfaz simple del programa no implica la presencia de ayuda normal. Continuando con la conversación sobre las capacidades de búsqueda, cabe señalar que, a pesar del análisis deficiente de las consultas, el programa proporciona un sistema de búsqueda interesante: el usuario puede seleccionar el tipo de archivos (imágenes, videos, música, etc.), ingresar un consulta de búsqueda y atributos de selección que son específicos para el tipo de archivo seleccionado. Por ejemplo, para archivos de sonido, estos pueden ser valores de etiquetas mp3 (artista, álbum, fecha, etc.), para imágenes, por ejemplo, puede elegir su tamaño (por resolución), en general, cada tipo tiene su ajustes propios. Después de buscar un determinado tipo de archivos, el programa mostrará una lista muy informativa en la ventana de resultados, y si su solicitud incluye archivos de otros tipos, puede abrirlos haciendo clic en un enlace específico.
Por separado, vale la pena mencionar la ventana de visualización de resultados. El contenido de estos archivos se muestra debajo de la lista de archivos encontrados (a menudo se usa un esquema similar en los clientes de correo electrónico). Es cierto que el texto solo se puede ver en su formato nativo y no hay un modo de visualización de texto sin formato, lo que no siempre es conveniente, ya que abrir un documento en este caso lleva más tiempo. Pero, dado que Copernic puede buscar imágenes y música, existe la posibilidad de visualizar estos archivos multimedia.
Se han descrito los principios básicos de este programa, ahora veamos qué nos puede ofrecer Copernic Desktop Search para trabajar con la red... En principio, puede mirar durante mucho tiempo, pero es poco probable que vea nada. En otras palabras, este programa no fue concebido como uno de red. Copernic Desktop Search es exclusivamente un motor de búsqueda doméstico.
Obviamente, el único uso (más lógico) de este programa es una computadora en casa. Aquí, hará frente a todas las consultas de búsqueda simples de los usuarios que consisten en una o dos palabras, encontrará la información necesaria y la separación de la búsqueda por tipo de archivo y soporte para archivos multimedia, junto con la indexación de fondo en modo de baja prioridad, junto con una interfaz agradable, solo dan fuerza al programa para ganar la confianza entre los usuarios sin experiencia.
Sitio oficial
Tamaño de distribución: 2,6 MbISYS DesktopHaga clic en la foto para ampliarla
Un programa muy potente. En cuanto al nivel de equipamiento con todo tipo de funciones, está cerca del próximo motor de búsqueda SearchInform de la lista. ¡Al mismo tiempo, el tamaño del archivo de instalación es más de 40Mb! Es difícil decir qué se podría meter en tales tamaños, porque el mismo SearchInform, con una funcionalidad similar, ocupa 15 Mb.
El proceso de instalación aquí tampoco es muy agradable, o más bien ni siquiera el proceso de instalación. Incluso antes de descargar el programa, se le pedirá que se registre; de lo contrario, nada. A continuación, la interfaz. Está muy bien hecho, nada superfluo llama la atención, sin embargo, estas son las impresiones de una persona que ya está algo acostumbrada a él. No será fácil para un principiante averiguar dónde y qué es, dónde hacer clic y dónde buscar finalmente. Se recomienda encarecidamente leer la ayuda antes de comenzar a trabajar; ahorre muchos nervios y tiempo. A todo lo demás, también se suma la total falta de soporte para el idioma ruso en el programa. No es bueno. Además, las ventanas aquí no están sobrecargadas con controles, pero esto tuvo el costo de varios módulos y el uso de ventanas adicionales. Por ejemplo, las consultas de búsqueda se ingresan mediante la ejecución de un programa y los índices se administran mediante otro programa. Las consultas de búsqueda también se ingresan aquí en cuadros separados que aparecen. Es difícil decir cuál es mejor: una interfaz sobrecargada o múltiples ventanas ubicuas, más bien, es cuestión de gustos.
En cuanto a la creación de índices, el programa proporciona opciones para simplificar el proceso de configuración de opciones para un nuevo índice. Estas funciones incluyen varias plantillas listas para usar para crear índices para Mis documentos, Correo, Correo y documentos, Carpeta específica, Carpeta con tipos de archivos seleccionados y más. Estas plantillas facilitan la creación de índices en la primera etapa. La utilidad para trabajar con índices tiene una interfaz no muy buena que ahuyenta cierta complejidad (esta es una valoración muy subjetiva, la verdad), pero si te fijas, ofrece muchas opciones útiles y, en general, su uso no no causa mucha dificultad. ISYS Desktop puede indexar datos de varias fuentes de datos y también proporciona muchas configuraciones flexibles para dicha indexación. Entre características adicionales para indexación: soporte para SQL, FTP, TRIM Context, WORLDOX 2002, scripts. Al crear un índice, si seleccionó la opción "Carpeta con una selección de tipos de archivos", tiene la oportunidad de seleccionar los tipos de archivos que se indexarán manualmente (por extensión). Debe decirse que simplemente hay una gran cantidad de tipos de archivos admitidos, pero no será posible agregar su propio tipo (extensión) a la lista existente. También puede notar la presencia de un programador de indexación. ISYS Desktop tardó 6 horas y 13 minutos en crear un índice y procesar 20 gigabytes de información, mostrando finalmente un buen tiempo y el tamaño del archivo creado: 7,9 GB.
Las capacidades de búsqueda de este programa no son malas. Lo que se usa en ISYS es mucho más potente que el soporte habitual para operaciones lógicas. De las funciones de búsqueda avanzada, el programa ofrece el uso de sinónimos, filtro de clasificación (por ruta, nombre y fecha de creación del archivo). El conjunto de operadores lógicos es algo más amplio que el conjunto estándar. Además de las operaciones lógicas, el programa le permite trabajar con muchos otros operadores que, en principio, pueden reemplazar algunos tipos de búsqueda, por ejemplo, la búsqueda con análisis se puede reemplazar completamente usando operadores especiales. Me sorprendió mucho que el programa no tenga búsqueda por morfología. Esta es una omisión grave, ya que la eficiencia de la búsqueda mejora mucho cuando se utiliza el análisis morfológico. Además, no hay una lista de palabras significativas, pero sí una extensa lista de palabras no significativas. También declaró tales funciones en la búsqueda como "búsqueda aproximada" y "análisis heurístico".
ISYS ofrece una selección de varios tipos de consultas de búsqueda, a saber, las visuales. Esto se hizo usando diferentes tipos ventanas para ingresar consultas de búsqueda, sin embargo, de hecho, ninguna ventana le permite usar tecnologías distintas de las enumeradas anteriormente.
Los resultados de la búsqueda son muy informativos y se muestran como una lista de documentos ordenados por relevancia. A continuación se muestra una vista previa del documento seleccionado. A diferencia de Copernic Desktop Search, la vista previa aquí está disponible solo en forma de texto sin formato, no fue posible lograr la visualización de documentos en el formato nativo, ya sea Word, Html o PDF, aunque en principio esto no es demasiado crítico. El programa le permite dividir los documentos encontrados en grupos según ciertos criterios (por defecto, están divididos por relevancia). También puede ver los documentos ya encontrados seleccionando carpetas separadas(esto es útil cuando el resultado produce una gran cantidad de documentos).
El uso del programa en una red corporativa también está bastante justificado, ya que brinda buenas oportunidades para organizar búsquedas en la red. El sistema de búsqueda se basa en la creación de un índice público, que contiene datos indexados de los recursos de la red pública.
De hecho, el programa de ISYS es digno de atención, al menos para familiarizarse con él. Este programa es un proyecto maduro con una gran cantidad de funciones (no siempre y no todos, por supuesto, las necesitan, pero aún así). Se desconocen las posibilidades de que el programa tenga algunas mejoras en el procesamiento de consultas de búsqueda, pero por el momento se puede recomendar para un uso casi universal. Y dado que todavía es demasiado pesado para los sistemas domésticos, los principales lugares para su instalación son las redes corporativas.
Sitio oficial:
Tamaño de distribución: 40 MbSearchInformHaga clic en la foto para ampliarla
Probablemente no valga la pena comenzar de inmediato con una descripción de la interfaz SearchInform. Primero debemos describir el proceso de instalación, o más bien uno de sus detalles: no podrá instalar el programa sin una conexión a Internet. El hecho es que antes del primer lanzamiento, el programa requiere el registro del usuario (sin cargo) y envía todos los datos ingresados al servidor. Aparentemente, los desarrolladores tuvieron que tomar tales medidas en la lucha contra la piratería, pero esto no afectó positivamente la facilidad de instalación.
La interfaz del programa está hecha de acuerdo con todas las reglas generalmente aceptadas, sin embargo, a primera vista, es algo engorrosa. Al usar el programa por primera vez, parece que es demasiado complicado, a veces no es fácil recordar en qué menú o pestaña está la opción deseada, sin embargo, con un uso prolongado, la interfaz ya no parece tan terriblemente complicada. Lo principal es leer la ayuda primero.
Habiendo tratado un poco con la interfaz, puede comenzar a crear un índice. El proceso en sí es muy simple y la velocidad de indexación, incluso a simple vista, es mucho más alta que la de todos los demás motores de búsqueda de la revisión. ¡Números claros de prueba muestran que SearchInform es el doble de rápido que dtSearch e iSYS en términos de velocidad de indexación! El programa indexó los datos proporcionados en la cantidad de 20 gigabytes en un tiempo récord: 3 horas y 17 minutos. Y el tamaño del índice creado resultó ser el más pequeño de 4,4 GB, 100 megabytes menos que el de Google Desktop Search.
El programa admite, además de archivos y carpetas normales, también indexación de correos electrónicos, conexión e indexación de bases de datos (!) Y otras fuentes externas (DMS, CRM), inmediatamente al indexar, puede especificar un diccionario para la búsqueda morfológica, y todos los atributos pueden ser archivos indexados. Después de crear un índice, al intentar realizar la primera búsqueda de prueba de documentos, uno puede llegar a cierta confusión: "aquí hay dos tipos de búsqueda, pero ¿cuál necesito?". Como se mencionó anteriormente, lo principal es leer la ayuda, luego todo se aclarará. El programa realmente puede realizar dos tipos de búsqueda: una búsqueda de frase y una búsqueda de documentos que son similares en contenido al texto de la consulta.
La descripción de todas las funciones principales para analizar una consulta de búsqueda se proporcionó anteriormente, por lo que ahora solo enumeraremos las capacidades de búsqueda proporcionadas por este programa. Comencemos con la búsqueda de frases: por supuesto, búsqueda morfológica, búsqueda de citas, operaciones lógicas, búsqueda de palabras (búsqueda por el comienzo de la palabra, por el final, por la parte media o una coincidencia completa), búsqueda de citas mixtas (cuando todas las palabras de la consulta deben estar presentes en el documento, pero no necesariamente en el orden ingresado), búsquedas de corrección de errores, uso de sinónimos, "búsqueda casi entre comillas" (busque la frase ingresada como una cita, pero puede haber otras palabras entre las palabras introducidas), etc. Algunas de las opciones enumeradas tienen sus propios ajustes específicos. Además, es posible usar un diccionario de palabras insignificantes, y el programa ya tiene una lista preparada de estas palabras, también puede usar un diccionario de palabras prioritarias para buscar (por supuesto, deberá completarlo tú mismo).
Aquí, en principio, repasamos brevemente todas las características principales de la búsqueda de frases.
Pasemos a la consideración de las características de este programa: la búsqueda de documentos similares. Los desarrolladores afirman que esto no es de ninguna manera una búsqueda de texto simple, es exactamente una "búsqueda de similar", así es como lo describen en todas partes, pero está bien, puedes llamarlo como quieras, lo principal es. Una breve búsqueda en Internet puede revelar rápidamente que la llamada "búsqueda similar" es un nuevo desarrollo en el campo del análisis de texto. Este sistema le permite encontrar textos que son similares en términos de contenido semántico. ¡Lo más agradable fue que después de realizar consultas de búsqueda de prueba, resultó que la teoría es bastante consistente con la práctica! El programa realmente busca documentos de contenido similar y los muestra en una lista, ordenados por porcentaje de similitud.
A continuación, veamos qué ofrece SearchInform (en concreto, su versión corporativa SearchInform Corporate) para trabajar en una red corporativa. Hay dos tipos de aplicaciones: del lado del servidor y del lado del usuario. La parte del servidor procesa de forma independiente los índices especificados, y los usuarios pueden usarlos para buscar, según los derechos de acceso que se les asignen. Los usuarios se pueden configurar automáticamente usando cuentas Windows (en términos profesionales, SearchInform utiliza la autenticación NTFS de Windows) y manualmente (los usuarios deberán agregarse por separado). A cada usuario se le puede permitir o denegar el acceso a ciertos índices, también puede combinar usuarios en grupos. En general, la configuración de red de SearchInform está por delante de Google en términos de flexibilidad y de Snoop Server en términos de conveniencia y simplicidad.
Sitio oficial:
Tamaño de distribución: 14,7 MbComparación de velocidad de indexación
Sistema de búsqueda Tiempo de indexación Tamaño del índice Bloodhound Pro Deluxe 4.5 38 horas 46 minutos 19 GB Escritorio Isys 7.0 6 horas 13 minutos 7,9GB DtSearch 7.0 6 horas 3 minutos 8,6GB Búsqueda empresarial de Google Desktop 8 horas 17 minutos 4,5GB Búsqueda en el escritorio de Copernic * 10 horas 51 minutos 7GB SearchInform 1.5.02 3 horas 17 minutos 4,4GB * La mayoría de los documentos .html y .txt que contenían texto en ruso, aunque estaban indexados, eran imposibles de encontrar excepto por sus nombres.
Todos los programas son dignos de atención.
Sobre la base de las pruebas y el examen cuidadoso de cada programa presentado en la revisión, se pueden sacar ciertas conclusiones. Por lo tanto, Google Desktop Search Copernic Desktop Search es bastante adecuado para un usuario sin experiencia como sistema de búsqueda de información del hogar. Hacen un buen trabajo con solicitudes simples, no cargan mucho al usuario con la configuración y, además, son completamente gratuitos. El intento de Google de ingresar al mercado de motores de búsqueda corporativos aún no se ha justificado por completo: para un trabajo completo, el programa debe complementarse con módulos adicionales y está lejos de ser fácil de configurar. Por tanto, al hablar de los nombres de Desktop Search, de Copernic, de Google, dejan tras de sí un nicho de buscadores "de escritorio".
Soluciones verdaderas y más poderosas: dtSearch, iSYS y SearchInform tampoco están listos para usar y ofrecen a los usuarios sus versiones de "escritorio". Pero a un precio razonable, a diferencia del software gratuito de Google y Copernic. Por supuesto, hay que pagar por la potencia, la velocidad y la funcionalidad. Pero los desarrolladores de dtSearch, iSYS y SearchInform se enfocan principalmente, por supuesto, en el sector corporativo. Redes, funcionalidad, indexación y velocidad de búsqueda: eso es lo que distingue a estos productos de sus "competidores". De acuerdo con los resultados de la prueba, se determinó el favorito: SearchInform. El programa brinda la capacidad de buscar documentos similares, tiene la indexación y la velocidad de búsqueda más altas, y tiene un buen conjunto de funciones.



