S. What is S.M.A.R.T. hard drives Smart hdd decryption
A hard drive is a complex electronic-mechanical device that has its own self-diagnostic technology that can predict the imminent failure of your hard drive. Which is usually a very sad event...
Technology S.M.A.R.T.(English) S elf M monitoring A scribing and R eporting T echnology ) - a technology for assessing the state of a hard disk with built-in self-diagnostic equipment, as well as a mechanism for predicting the time of its failure.
We will not consider this technology in detail, because. this is too broad a question, and each drive manufacturer has its own vision and the number of monitored parameters. Consider the most important from a practical point of view.
To do this, we need a program to view the monitored parameters.
In it, on the "Data storage-> SMART" tab, select the hard disk and the monitored parameters are displayed in the window:
01 Raw Read Error Rate- the number of reading errors. Modern disks have a very high data storage density, so they constantly read data with errors, and the information is restored due to the ECC error correction code. It is these errors that this parameter considers. AT hard drives These non-critical errors are shown by Seagate, other manufacturers prefer to modestly keep silent about this. For Seagate drives, the state can be considered very good when the Raw Read Error Rate and Hardware ECC Recovered parameters are equal. This means that how many errors there were, so many were corrected using the correction code. If these values are not equal, then you should not be afraid. This is not a critical parameter and the disk can live for years without any problems.
03 Spinup Time- time to spin up the disk to a working state. You should only worry if the value is less than half of the initial value. But there are still a few nuances, such as how many platters are in the hard drive. The maximum currently is 5 platters (Hitachi), of course, it will take more time to spin up such a package of disks than for the 1st platter. Nobody canceled the force of inertia.
04 Start/Stop Count- total number of starts/stops of the spindle. For Seagate, the number of times the spindle stops when going into power save mode.
05 Reallocated Sector Count- number of reassigned sectors. That is, when a drive detects a read/write error, it marks the sector as "remapped", and transfers the data to a specially designated spare area. In general, this is a terrible parameter, if its value is more than 10, then this at least means that it is time to check the entire surface of the disk to understand whether this process will continue. Judging by practice, laptop disks suffer from reassigned sectors somewhere after a year of use. Because they work in very harsh conditions. I'm not talking about strikes - most are more or less protected from this. The reason is temperature. The laptop case is usually poorly ventilated and the disk overheats, then we turn off the laptop and go where? That's right, on the street! And it's -10 Celsius. That's just the rate of heating-cooling and destroys the delicate magnetic layer on the disc plates. According to the specifications of all disk manufacturers, the so-called "temporal temperature gradient", that is, the rate of temperature change should be no more than 20 degrees / hour - in working condition and no more than 30 degrees / hour in the off state. This rule is always violated, but for laptops it is especially often and cruelly.
09 Power-on Time Count (Power-on Hours)- the amount of time spent in the on state. Usually for modern drives it is measured in hours (for Fujitsu in seconds). For old Maxtor drives, not for those now produced by Seagate under this brand, but for original Maxtor drives, the time changes in minutes. This is very useful parameter if you buy an old disk, then you want to know how much it has worked in its life. And besides, usually this time coincides with the time of the computer and you can determine how many people spend at the computer on average. As practice and my survey on one of the major forums dedicated to computer hardware show, disks with an operating time of more than 20,000 hours (approximately 2.5 years of continuous operation) already have some kind of defects, for example, the same "reassigned" sectors and are not so far from senile death. From the same manufacturer's specifications, you can find out that discs designed for desktop computers are not designed to work around the clock, but are designed to work in 8/5 mode, that is, 8 hours 5 days a week. This works out to about 2400 hours per year. And it turns out that the warranty is calculated for 3 years - 7200 hours, for 5 years - 12000 hours. Not so much, considering that there are 8760 hours in a year.
0A Spinup Retry Count- The number of retries to spin up disks to operating speed if the first attempt was unsuccessful. If the attribute value increases, then mechanical/bearing damage is likely. It is very rare, modern discs are made with hydrodynamic bearings, and in the event of a malfunction of such a bearing, it jams immediately and tightly or works happily ever after. Not so long ago, Toshiba drives and, to a lesser extent, Western Digital suffered greatly from this. Jamming occurs from overheating.
0C Power Cycle Count- number of disk on/off cycles.
C2 Temperature- disk temperature. Unfortunately, the temperature sensors are on the disks. different manufacturers in different places, so there are overestimations and underestimations of the real temperature. But on average, as shown by a recent Google study, the optimal operating temperature is in the range of 35 to 45 degrees. Above 50 degrees, operation is highly discouraged, but such temperatures and even higher can often be seen in laptops.
The number of sectors that are candidates for replacement. They have not yet been identified as bad, but reading from them is different from reading a stable sector, these are the so-called suspicious or unstable sectors. In the case of a successful subsequent reading of the sector, it is excluded from the list of candidates. In the event of repeated erroneous reads, the drive tries to recover it and performs a remapping operation. A non-zero value usually occurs if there are already remapped sectors on the disk. If this is the case, then with a high probability we can say that the disk is actively "stripping", that is, the magnetic layer of the hard disk platters is being destroyed.
The number of uncorrected errors, that is, severe damage to the disk surface. Such errors appear when the space in the reserve zone of the disk for sector remapping runs out. They can also appear when the power is suddenly turned off at the moment when the disk is writing data - these are the so-called "software bad blocks". If their number is one or two, and the rest of the parameters relating to the surface of the disk are normal, then you should not worry. If it is large, then the data must be saved and the "body to be taken out" should be prepared. :)
C7 Ultra ATA CRC Error Rate- number of transmission errors in the external interface. Usually the cable or poor contact of the cable with the connectors is to blame, especially on SATA drives. Occurs quite often.
C8 Write Error Rate- Errors when writing to disk. Occurs rarely. Usually on very old discs. If there are errors, then this means the physical wear of the hard disk drive. Or with serious damage to the surface of the disk. (when the number of reassigned sectors and uncorrected errors exceeds all reasonable values).
So we briefly reviewed the main parameters of the hard drive self-diagnosis system. If you want to know more about this, you can refer to Wikipedia materials:
Unfortunately, SMART cannot always predict disk death. As the study of the same Google showed, about 50% of disks die abruptly and for no apparent reason. But in one this technology is definitely useful. Using it, you can quickly find out the state of the disk surface, that is, the parameters:
05 Reallocated Sector Count
C5 Current Pending Sector Count
C6 Offline Uncorrectable Sector Count
And it is very useful to know the time that a disk has worked in its life in order to roughly guess what you can expect from it.
And now a little about the future. A sufficient number of offers of really "hard drives" have already appeared on sale. They are made on flash-type solid-state memory chips and are much more reliable both in terms of mechanical stress and temperature. However, manufacturers have not yet agreed on a standard self-diagnostic system for this type of drive. But it will be much easier than for the good old electromechanical drives. And most importantly, it will predict the possibility of failure with a much higher probability! Flash memory is more predictable in this sense. Well, let's wait for this bright future!
Modern hard disks quite “smart” devices and, in addition to the main properties inherent in them as data storage and processing devices, support the technology of self-testing, state analysis, and accumulation of statistical data on the deterioration of their own characteristics S.M.A.R.T. (S elf- M monitoring A nalysis a nd R eporting T echnology). Basics of S.M.A.R.T. were developed in 1995 by the joint efforts of leading manufacturers of hard disk drives (HDD). In subsequent years, S.M.A.R.T standards have been refined in accordance with changes in technology and equipment (SMART II and SMART III) and continue to improve at the present time.
A hard drive, starting from the moment of its manufacture, constantly monitors certain parameters of its condition and reflects them in special characteristics - attributes(Attribute), stored in a permanent storage device, as a rule, in a specially allocated part of the disk surface, accessible only to the internal firmware of the drive - service area. Attribute data can be read, according to the ATA specification ( AT A ttachment) by SMART support commands (SMART READ DATA and more than a dozen commands), which are transferred to the drive by special software, such as utilities from equipment manufacturers or universal programs HDD testing and monitoring (udisks, smartctl, GSmartControl, gnome-disks, etc.). Modern ATA standards include support for the SCT (SMART Command Transport) protocol, which reads device statistics logs. The device statistics log is a read-only SMART log sent by the drive when it receives READ LOG EXT, READ LOG DMA EXT, or SMART READ LOG commands.
The attribute is a characteristic of a certain state of the hard drive, which changes during operation, taking on a numeric value from the maximum value set at the time of manufacture of this device, to the minimum value, upon reaching which the performance of the drive is not guaranteed. All attributes are identified by their digital number, most of which are interpreted in the same way by hard drives of different models. Some of them may only be used by a specific hardware manufacturer, and are supported by certain drive models. So, for example, an attribute with id 7 , which characterizes the number of errors in the installation of heads on the required track of the disk surface Seek_Error_Rate does not make sense for solid-state drives (SSD) and, accordingly, is not supported by them, and the attribute with the identifier 9 characterizing the total operating time of the drive for the entire period of operation and denoted as Power_On_Hours,supported by both SSD and traditional HDD.
Attributes consist of several fields, (most commonly referred to as Val, Worst, Tresh, RAW), each of which is a specific indicator that characterizes the technical condition of the drive on this moment time. S.M.A.R.T. Readers display the contents of the attributes, usually in the form of several columns:
Pre-Failure (PF, 01h)- upon reaching the threshold value of this type disk attributes need to be replaced. Sometimes this bit of flags is denoted as Life Critical (CR) or Pre-Failure warranty (PW)
O nline test (OC, 02h) - the attribute updates the value when performing off-line / on-line built-in SMART tests;
P erfomance R elated (PE or PR , 04h) – attribute characterizes performance;
E rror R ate (ER , 08h) – attribute reflects hardware error counters;
E vent C ounts (EC, 10h) - the attribute is an event counter;
S elf P reserving (SP, 20h) - self-reserving attribute;
Some of the programs can interpret the flags as textual descriptions that are similar in meaning to those discussed above. One attribute can have multiple flag values set to one, for example, an attribute with id 05
reflecting the number of sectors reassigned due to failures from the spare area, has the SP + EC + OC flags set - self-saving, event counter, updated when the drive is offline and online.
To analyze the state of the drive, perhaps the most important attribute value is value- conditional number (usually from 0 to 100 or up to 253) set by the manufacturer. Meaning value is initially set to the maximum when the drive is manufactured, and decreases as the drive degrades. For each attribute, there is a threshold value, upon reaching which, the manufacturer does not guarantee its performance - the field Threshold. If the value value approaching or falling below Threshold, - it's time to change the drive.
The list of attributes and their values are not rigidly standardized and some of them may be determined by the drive manufacturer, but the main part is interpreted in the same way. For example, an attribute with id 05 (reallocated sector count) will characterize the number of disk sectors rejected and reassigned from the spare area, both for devices manufactured by Seagate Technology, and for devices manufactured by Western Digital. The set of supported attributes depends on the drive model and may vary significantly in composition for different models.
Most common software tool to obtain S.M.A.R.T data in a Linux environment, is a utility smartctl from the kit smartmontools, usually included in the default software any distribution. If necessary, you can update the version, as well as download documentation in English, on the smartmontools.org project website.
To work with the utility smartctl superuser rights required root.
Format command line smartctl:
smartctl device options
Examples of using smartctl
smartctl --help or smartctl --usage- display a hint about using the command.
Options smartctl:
-V, --version, --copyright, --license- display version, copyright and license information.
-i, --info- display identification information for the device.
-g NAME, --get=NAME- display disk settings options (all, aam, apm, lookahead, security, wcache, rcache, wcreorder)
-a, --all- display all SMART data of the specified drive.
-x, --xall- display all technical data for the specified drive.
--scan- search for disk devices.
-q TYPE, --quietmode=TYPE set output verbosity mode for smartctl (errorsonly, silent, noserial)
-d TYPE, --device=TYPE- set device type (ata, scsi, sat[,auto][,N][+TYPE], usbcypress[,X], usbjmicron[,p][,x][,N], usbsunplus, marvell, areca,N /E, 3ware,N, hpt,L/M/N, megaraid,N, cciss,N, auto, test) smartctl cannot determine it automatically.
-b TYPE, --badsum=TYPE- set reaction to checksum errors detection (warn, exit, ignore)
-r TYPE, --report=TYPE- option intended for developers smartmontools and allows you to get detailed information when performing transactions of the I / O device control function ioctls(ioctl, ataioctl, scsiioctl and debug level). Details - man smartctl
-n MODE, --nocheck=MODE- the mode of prohibition to perform tests for power saving modes (never, sleep, standby, idle). Typically used to prevent the spindle motor from starting with the smartctl command.
-s VALUE, --smart=VALUE- disable or enable SMART (on / off)
-o VALUE, --offlineauto=VALUE- disable or enable automatic execution of tests in non-interactive mode (in drive idle mode), accepted values - on/off
-S VALUE, --saveauto=VALUE autosave attributes (on/off)
-s NAME[,VALUE], --set=NAME[,VALUE]- disable/enable drive hardware parameters (aam,, apm,, lookahead,, security-freeze, standby,, wcache,, rcache,, wcreorder,)
-H, --health- display the drive status (SMART health status)
-c, --capabilities- display information about the supported SMART capabilities of the specified hard drive.
-A, --attributes- display SMART attributes
-f FORMAT, --format=FORMAT- set the format of displayed SMART attributes (old, brief, hex[,id|val]). Basically, it affects the format of displayed values of attribute identifiers and the format of displaying their flags:
old- attribute identifiers are displayed in decimal system reckoning, flag values are displayed in hexadecimal and interpreted as text.
hex- the same as in the previous case, but attribute IDs are displayed in hexadecimal notation.
brief - compact output, identifiers are displayed in decimal notation, flags are displayed as characters with decoding at the bottom of the table:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE 1 Raw_Read_Error_Rate POSR-- 114 100 006 - 78309029 . . . . . . 254 Free_Fall_Sensor -O--CK 100 100 000 - 0 ||||||_ K auto-keep |||||__ C event count ||||___ R error rate |||____ S speed/performance || ______ O updated online |______ P prefailure warning
-l TYPE, --log=TYPE- display the specified device log (selftest, selective, directory[,g|s], xerror[,N][,error], xselftest[,N][,selftest],background, sasphy[,reset], sataphy[,reset ], scttemp, scttempint,N[,p], scterc[,N,M], devstat[,N], ssd, gplog,N[,RANGE], smartlog,N[,RANGE]
-v N,OPTION , --vendorattribute=N,OPTION- set a parameter for a manufacturer-defined attribute with identifier N
-F TYPE, --firmwarebug=TYPE- adaptation of the program to account for errors in the hardware firmware of the drive (none, nologdir, samsung, samsung2, samsung3, xerrorlba, swapid)
-P TYPE, --presets=TYPE- preset disk options. By default, having found information about the drive in its database, the utility smartctl, uses the set of options available for this model. Option use- use presets for this drive, ignore- do not use, show- display presets for this disk, showall- display presets for the specified model. Examples:
smartctl -P ignore /dev/hdb- ignore presets for /dev/hdb;
smartctl -P show /dev/sdb- display presets for the specified drive;
smartctl -P showall 'ST9250315AS'- - display presets for the specified disk model - ST9250315AS;
smartctl -P showall 'ST3750515AS' 'SD15'- display presets for the specified disk model ST3750515AS with SD15 firmware;
-B [+]FILE, --drivedb=[+]FILE- read and change the database of disk models from the file FILE. The “+” sign in front of the file name means adding new records to the database before the existing ones.
By default, the database is stored in /usr/share/smartmontools/drivedb.h
DEVICE SELF-TEST OPTIONS =====
-t TEST, --test=TEST- start the test execution TEST Run test. TEST: offline, short, long, conveyance, force, vendor,N, select,M-N, pending,N, afterselect,
-C, --captive- execution of tests in drive capture mode. Used in conjunction with the parameter -t for tests not in mode offline. Using this option may cause the device to be busy for the duration of the test and result in system disruption and data loss. Do not use the option -c to perform tests on drives with mounted partitions. For SCSI devices, this option means running built-in tests in "Foreground mode" .
-X, --abortion- force quit a test running without a key --captive.
Examples of using smartctrl.
smartctl --info /dev/sdb- display identification information for the /dev/sdb device. Example command output:
=== START OF INFORMATION SECTION === Device Model: ST9500620NS Serial Number: 9XF0AW8T Firmware Version: SN01 User Capacity: 500,107,862,016 bytes Device is: Not in smartctl database ATA Version is: 8 ATA Standard is: ATA-8-ACS revision 4 Local Time is: Tue Oct 28 15:05:31 2014 MSK SMART support is: Available - device has SMART capability. SMART support is: Enabled
smartctl --all /dev/hda- display all SMART data for the device /dev/hda
Example of displayed data:
=== START OF INFORMATION SECTION === Device Model: ST9500620NS Serial Number: 9XF0AW8T Firmware Version: SN01 User Capacity: 500,107,862,016 bytes Device is: Not in smartctl database ATA Version is: 8 ATA Standard is: ATA-8-ACS revision 4 Local Time is: Tue Oct 28 15:05:45 2014 MSK SMART support is: Available - device has SMART capability. SMART support is: Enabled === START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED General SMART Values: Offline data collection status: (0x82) Offline data collection activity was completed without error. Auto Offline Data Collection: Enabled. Self-test execution status: (0) The previous self-test routine completed without error or no self-test has ever been run. Total time to complete Offline data collection: (634) seconds. Offline data collection capabilities: (0x7b) SMART execute Offline immediate. Auto offline data collection on/off support. Suspend Offline collection upon new command. Offline surface scan supported. Self test supported. Conveyance Self-test supported. Selective Self-test supported. SMART capabilities: (0x0003) Saves SMART data before entering power-saving mode. Supports SMART auto save timer. Error logging capability: (0x01) Error logging supported. General Purpose Logging supported. Short self-test routine recommended polling time: (1) minutes. Extended self-test routine recommended polling time: (102) minutes. Conveyance self-test routine recommended polling time: (2) minutes. SCT capabilities: (0x10bd) SCT Status supported. SCT Feature Control supported. SCT Data Table supported. SMART Attributes Data Structure revision number: 10 Vendor Specific SMART Attributes with Thresholds: ID # ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000f 082 064 044 Pre-fail Always - 190 274 202 3 Spin_Up_Time 0x0003 096 096 000 Pre-fail Always - 0 4 Start_Stop_Count 0x0032 100,100,020 Old_age Always - 72 5 Reallocated_Sector_Ct 0x0033 100 100 036 Pre-fail Always - 0 7 Seek_Error_Rate 0x000f 070 060 030 Pre-fail Always - 11302732 9 Power_On_Hours 0x0032 073,073,000 Old_age Always - 24037 10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 72 184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0188 Command_Timeout 0x0032 100 100 000 Old_age Always - 0 189 High_Fly_Writes 0x003a 100 100 000 Old_age Always - 0 190 Airflow_Temperature_Cel 0x0022 081 048 045 Old_age Always - 19 191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0192 Power-Off_Retract_Count 0x0032 100,100,000 Old_age Always - 38,193 Load_Cycle_Count 0x0032 100,100,000 Old_age Always - 73,194 Temperature_Celsius 0x0022 019,052,000 Old_age Always - 19 (0 14 0 0) 195 Hardware_ECC_Recovered 0x001a 118 100000 Old_age Always - 190 274 202 197 Current_Pending_Sector 0x0012 100,100,000 Old_age Always - 0198 Offline_Uncorrectable 0x0010 100,100,000 Old_age Offline - 0199 UDMA_CRC_Error_Count 0x003e 200,200,000 Old_age Always - 0 SMART Error log Version: 1 No Errors Logged SMART Self-test log structure revision number 1 No self-tests have been logged. SMART Selective self-test log data structure revision number 1 SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS 1 0 0 Not_testing 2 0 0 Not_testing 3 0 0 Not_testing 4 0 0 Not_testing 5 0 0 Not_testing Selective self-test flags (0x0): After scanning selected spans, do NOT read-scan remainder of disk. If Selective self-test is pending on power-up, resume after 0 minute delay.
smartctl -A -v 9,minutes /dev/hda- display all SMART attribute data for a device /dev/hda and attribute with id 9 (power-on time) should be interpreted as an internal value given in minutes rather than hours.
smartctl --smart=on --offlineauto=on --saveauto=on /dev/hda- enable SMART for /dev/hda disk, enable automatic execution offline tests and self-saving attributes. The command can be run on a running system. In fact, this is the installation of standard operating parameters for a conventional disk drive.
smartctl --test=long /dev/hda- run extended built-in tests for the /dev/hda drive. The command can be used on a running system. To view the results of test execution, use the command to display the internal log after the test is completed.
smartctl -l selftest /dev/hda
smartctl --attributes --log=selftest --quietmode=errorsonly /dev/had- Display internal self-test log data and error attributes.
smartctl -s on -t offline /dev/hdc- enable SMART and perform an offline test for the /dev/hdc drive. If an error is detected during testing, information on it will be written to the internal log, which can be viewed using the parameter -l error.
smartctl -q silent -a /dev/had- check SMART data without displaying received information. Usually used in scripts. After the command is executed, the return code is checked (variable $? command shell) to determine whether the value of any attribute has gone beyond the limit value or whether there is an error entry in the device logs.
smartctl -q errorsonly -H -l selftest /dev/had- output information only if there is an erroneous SMART condition or if any of the internal tests fail.
smartctl -t select,10-100 -t select,30-300 -t afterselect,on -t pending,45 /dev/hda- perform an internal test in the specified area of LBA blocks and, after its completion, scan the rest of the disk. If the power is turned off during the scan, continue scanning 45 minutes after the power is turned on.
smartctl --all --device=3ware,0 /dev/sda- get SMART data for the first ATA disk connected to the 3ware RAID controller.
smartctl -a -d 3ware,0 /dev/twe0- get SMART data for the first ATA disk connected to a 3ware RAID 6000/7000/8000 RAID controller.
smartctl -a -d 3ware,0 /dev/twa0- get SMART data for the first ATA disk connected to a 3ware RAID 9000 RAID controller
smartctl -t short -d 3ware,3 /dev/sdb- run short internal tests for disk 4, second disk SCSI device /dev/sdb
smartctl -a -d hpt,1/3 /dev/sda- to get data SMART drive connected to channel 3 of the first HighPoint RocketRAID controller
Explanation of S.M.A.R.T attributes
Attribute identifiers are given in decimal notation, and those in brackets are in hexadecimal.
Assessment of the technical condition of the hard drive according to S.M.A.R.T data
Supported Attribute Set specific model hard drive, even if it is minimal, allows you to determine the technical condition and prospects for the operation of the device with high reliability. You can determine the time spent in the on state by the value of the attribute 9 , and together with the attribute value 12 - the number of power on / off, and therefore - round-the-clock or periodic operation. Intensity of use, temperature, negative external influences- all these facts are easily tracked by the absolute values of the corresponding attributes. Similarly, you can evaluate the level of equipment wear, the quality of the surface and the write / read path.
Minimally informative disk status monitoring can be performed even at the BIOS level. In case of reaching the critical value of any attribute that characterizes the health, with S.M.A.R.T status monitoring enabled in BIOS settings, the operating system loading is suspended and the following message is displayed on the screen:
Primary Master Hard Disk: S.M.A.R.T status BAD!, Backup and Replace.
Press F1 to Resume
Thus, without installing or running additional software, it is possible to timely determine the fact of the critical state of the drive using Base System Input-Output (BIOS) when you turn on the computer.
The technical condition of a hard disk that has not reached the critical threshold is characterized by the absolute value of the attributes that reflect the counters of failures detected and corrected by the drive hardware.
Change absolute values attributes must be considered in dynamics, and in a logical relationship with each other.
Running built-in S.M.A.R.T tests
The set of built-in S.M.A.R.T tests is determined by the manufacturer and may vary significantly for different hard drive models. Basically, the built-in SMART tests are short tests (short self-test) and long ones (extended sels-test). The short tests scan a small portion of the disk surface as defined by the manufacturer and run for about 1 minute on average. Long tests scan the entire working surface of the disk and can run, depending on the speed and volume of the disk, even for several hours. Also, for modern disks, you can perform selective tests (selective self-test), the parameters of which are set by the user and tests after transporting the device (conveyance self-test). Tests can be aborted if the drive's capture mode (captive) is not set and the drive supports the test abort command. Regarding drive capture mode when running tests captive, then you need to use it carefully if the disk is used by the system.
Examples:
smartctl --test=short /dev/sdb- run a short test. In response to the command, information will be displayed:
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION === Sending command: "Execute SMART Short self-test routine immediately in off-line mode". Drive command "Execute SMART Short self-test routine immediately in off-line mode" successful. Testing has begun (previous test aborted). Please wait 1 minute for test to complete. Test will complete after Fri Dec 5 16:08:09 2014 Use smartctl -X to abort test.
Which means that a command was sent to the disk to perform a short test, the disk accepted it successfully, the test will last 1 minute, and you can use the smartctl –X command to force it to stop.
The result of the test execution can be checked by viewing the test log with the command smartctl –l selftest. Log information will be received in response self test:
=== START OF READ SMART DATA SECTION === SMART Self-test log structure revision number 1 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Short offline Completed without error 00% 831 -
Log columns: Num- record number.
Test_Description- description of the test.
Status- completion status (completed without errors)
Remaining- percentage of time remaining until the end of the test, if it is not yet completed (00%)
Lifetime(hours)- time of operation of the drive from the beginning of operation.
LBA_of_first_error- number of the LBA logical block where the first error was detected during the test execution. AT this example, there are no errors.
To run a long test, use the command:
smartctl --test=long /dev/sdb
In response to the command, information about the start of the test is displayed:
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION === Sending command: "Execute SMART Extended self-test routine immediately in off-line mode". Drive command "Execute SMART Extended self-test routine immediately in off-line mode" successful. Testing has begun. Please wait 70 minutes for test to complete. Test will complete after Fri Dec 5 17:15:44 2014
As you can see, the long test for this drive model will run for 70 minutes.
The result of the execution can be checked with the command smartctl –l selftest /dev/sda
List of ATA commands for working with S.M.A.R.T
SMART_READ_VALUES 0xd0 SMART_READ_THRESHOLDS 0xd1 SMART_AUTOSAVE 0xd2 SMART_SAVE 0xd3 SMART_IMMEDIATE_OFFLINE 0xd4 SMART_READ_LOG_SECTOR 0xd5 SMART_WRITE_LOG_SECTOR 0xd6 SMART_ENABLE 0xd8 SMART_DISABLE 0xd9 SMART_STATUS 0xda SMART_AUTO_OFFLINE 0xdb
More on the topic of hardware in Linux:
Sequence of actions in the presence of S.M.A.R.T. hard drive or SSD errors. How to fix disk and recover lost data. When you boot your computer or laptop, S.M.A.R.T. appears. hard drive or ssd error? After this error, the computer does not work as before, and you are afraid about the safety of your data? Don't know how to fix the error?
Actual for OS: Windows 10, Windows 8.1, Windows Server 2012, Windows 8, Windows Home Server 2011, Windows 7 (Seven), Windows Small Business Server, Windows Server 2008, Windows Home Server, Windows Vista, Windows XP, Windows 2000, Windows NT.
What to do with SMART error?
Step 1: Stop using the failed HDD
Receiving an error diagnostic message from the system does not mean that the drive has already failed. But in case of S.M.A.R.T. errors, you need to understand that the disk is already in the process of failure. A complete failure can occur both within a few minutes, and after a month or a year. But in any case, this means that you can no longer trust your data to such a disk.
You need to take care of the safety of your data, create backup or transfer files to another storage medium. Along with the safety of your data, you must take steps to replace the hard drive. The hard drive where the S.M.A.R.T. errors should not be exploited - even if it does not completely fail, it can partially damage your data.
Of course, HDD may fail without warning S.M.A.R.T. But this technology gives you the advantage of warning you that a drive is about to fail.
Step 2: Recover deleted disk data
In the event of a SMART error, data recovery from the disk is not always required. In the event of an error, it is recommended to immediately create a copy of important data, as the disk may fail at any time. But there are errors in which it is no longer possible to copy data. In this case, you can use the recovery program data hard disk - Hetman Partition Recovery.

For this:
- Download the program, install and run it.
- By default, the user will be prompted to use File recovery wizard. Pushing a button "Further", the program will prompt you to select the drive from which you want to recover files.
- Double click on the failed drive and select the type of analysis you want. Choose "Full Analysis" and wait for the disk scanning process to complete.
- After the scanning process is completed, you will be provided with files to restore. Highlight necessary files and press the button "Reestablish".
- Choose one of the suggested ways to save files. Do not save recovered files to a disk with an error.
Step 3: Scan the disk for bad sectors
Run a scan of all hard disk partitions and try to fix any errors found.

To do this, open the folder "This computer" and click right click mouse on disk with SMART error. Select Properties / Service / Check In chapter Checking the disk for errors.
As a result of scanning, errors found on the disk can be corrected.
Step 4: Reduce disk temperature
Sometimes, the cause of the “S M A R T” error may be the exceeding of the maximum allowable operating temperature of the disk. This error can be fixed by improving the ventilation of the computer. First, check if your computer is equipped with sufficient ventilation and if all fans are working properly.
If you find and fix a ventilation problem, after which the disk's operating temperature drops to a normal level, then the SMART error may no longer occur.
Step 5:
Open folder "This computer" and right-click on the disk with the error. Select Properties / Service / Optimize In chapter Disk optimization and defragmentation.

Select the drive you want to optimize and click Optimize.
Note. In Windows 10, disk defragmentation and optimization can be configured to run automatically.
Step 6: Buy a new hard drive
If you encounter a SMART hard drive error, then purchasing a new drive is only a matter of time. Which hard drive you need depends on your computer style and the purpose for which it is being used.
What to look for when purchasing a new drive:
- Disk type: HDD, SSD or SSHD. Each type has its pros and cons, which are not critical for some users and are very important for others. The main ones are the speed of reading and writing information, volume and resistance to repeated rewriting.
- The size. There are two main drive form factors: 3.5" and 2.5". The disk size is determined in accordance with the installation location of a particular computer or laptop.
- Interface. Main hard drive interfaces:
- SATA
- IDE, ATAPI, ATA;
- SCSI
- External drive (USB, FireWire, etc.).
- Specifications and performance:
- Capacity;
- Read and write speed;
- The size of the memory buffer or cache;
- Response time;
- Fault tolerance.
- S.M.A.R.T.. The presence of this technology in the disk will help determine possible mistakes its work and prevent data loss in time.
- Equipment. This item includes the possible presence of interface or power cables, as well as warranty and service.
How to reset SMART error?
SMART errors can be easily reset in the BIOS (or UEFI). But the developers of all operating systems We strongly do not recommend doing this. If the data on the hard disk is of no value to you, then the output of SMART errors can be disabled.
To do this, do the following:
- Restart your computer, and by pressing the key combination indicated on the boot screen (they are different for different manufacturers, usually "F2" or Del) go to BIOS (or UEFI).
- Go to: advanced > SMART settings > SMART self test. Set value Disabled.
Note: the location of the deactivation of the function is indicated approximately, since depending on the BIOS versions or UEFI, the location of this setting may vary slightly.
Is HDD repair worth it?
It is important to understand that any of the ways to eliminate SMART errors is self-deception. It is impossible to completely eliminate the cause of the error, since the main cause of its occurrence is often the physical wear of the hard drive mechanism.
To eliminate or replace malfunctioning hard drive components, you can contact the service center of a special laboratory for working with hard drives.
But the cost of work in this case will be higher than the cost of a new device. Therefore, it makes sense to do repairs only if it is necessary to restore data from an already inoperable disk.
SMART error for SSD drive
Even if you have no claims to work SSD drive, its performance gradually decreases. The reason for this is the fact that SSD memory cells have a limited number of write cycles. The wear resistance function minimizes this effect, but does not completely eliminate it.
SSD drives have their own specific SMART attributes that signal the state of the disk's memory cells. For example, “209 Remaining Drive Life”, “231 SSD life left”, etc. These errors can occur when cells are degraded, which means that the information stored in them can be corrupted or lost.
The cells of an SSD disk in the event of a failure are not restored and cannot be replaced.
Equipped with a special firmware for self-diagnosis S.M.A.R.T. (self-monitoring, analysis and reporting technology). This technology allows you to monitor the state of the HDD, analyze its operation and predict failure. "SMART" monitors over 40 parameters, the result for each of which is entered in a special table. Analysis of S.M.A.R.T. allows you to detect vulnerabilities and predict the failure of a hard drive.
This article will tell you how to view the SMART of a hard drive, decipher its readings, and what parameters should be given special attention. It should be noted that the information is presented in a structured way, but special software is required to extract data from it.
How to watch S.M.A.R.T. hard drive. Decryption of parameters.
To check the "SMART" parameters, this function must be enabled in the system. This is true for computers manufactured before 2010. They have an HDD S.M.A.R.T option in the BIOS. Capability, the inclusion of which allows you to fully track the "SMART". In new PCs, the question “how to enable S.M.A.R.T. on the hard drive? irrelevant - everything is enabled by default.
To view HDD status parameters, you need a special utility for working with hard drives (Victoria, HD Tune, HDD Scan) or complex diagnostic programs(Everest or its "successor" Aida64). They allow you to display the table in an easy-to-understand way.
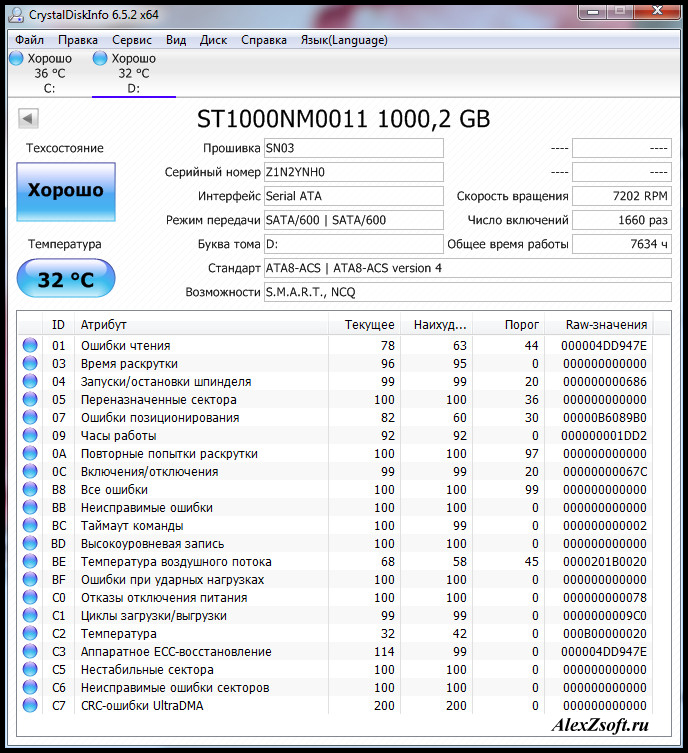
Let's analyze the parameters on the example of "Victoria". As you can see from the image, the hard drive (in this case it is a 200 GB Seagate with an outdated IDE interface) does not support all "SMART" commands and fixes some of the parameters.
In the header of the table, you can see the parameter ID, its name, VAL, Wrst, Tresh and Raw values, as well as the estimated Health column.
- ID – parameter number in the general list of analyzed criteria.
- VAL is its current value in abstract units (usually a percentage of the ideal indicator).
- Wrst is the worst value that the hard drive has ever reached.
- Tresh is a conditional threshold for the VAL value, upon reaching which the system notifies of the impending "death" of the HDD.
- RAW is an expression of the VAL parameter in numerical format (the number of hours of operation / failures / errors / bugs).
The Health parameter allows you to assess the state of the HDD for people who are unfamiliar with the intricacies of computer hardware or English language. He assigns the usual score of 1 to 5 points to each of them.
When analyzing the state of a hard drive, you should pay attention to VAL (comparing with the Tresh column) and RAW (for an objective assessment). In the above example, it can be seen that the hard drive has experienced many read errors (for Seagate, Fujitsu and Samsung, you can not look at this column - all errors are recorded here) and has a long operating time (parameter 9). The table shows that the number of hardware error corrections (parameter 195) is quite high. The rest of the "SMART" values are normal, or close to it. It is important that parameter 5 (Reallocated Sectors Count) is OK. This means that the number of bad sectors is small (11 in this case) and nothing threatens the disk itself yet.

If parameter 5 differs with alarming values, the health of the HDD is at risk. In the above screenshot, the Reallocated Sectors Count graph indicates that the railway is close to failure. In this case, it is a system failure (a mismatch between RAW zero and critical VAL indicates this), and a SMART hard drive recovery is required to bring it back to normal. But usually such information indicates that the HDD is about to break down, and it can no longer be used normally.
How to reset or restore S.M.A.R.T. hard drive
We can't go into detail on how to reset a SMART hard drive. Although this action is not criminal (unlike the same IMEI change of a smartphone), it can help unscrupulous dealers sell faulty hard drives under the guise of new ones. But for users who need to know how to recover a SMART hard drive to get it back in service after a software failure, let's explain the situation in general terms.
- To reset S.M.A.R.T. (just like other service tasks) a hard drive connection via the COM interface is required. To do this, manufacturers equip the HDD with a special connector of 4 or 5 pins. It is located next to the slots for data and power cables. Newer computers often do not have a COM jack on the rear panel, so a special USB-COM board takes over its function.

Hard drive interface connectors

Hi all! In the last article, we reviewed . And today we will look at how to look hard health disk, for example, in order to know that nothing will happen to it in the near future. Well, or it happened and you still have time to save the data.
To get started, download the free program:
We also run:

- Select the disk whose health you want to check
- Next, click on the magnifying glass
- And press SMART

In the Attribute Name cell, the name of the smart test. You can find more detailed information in the file by clicking on the download button. This is information from Wikipedia. The file will also contain critical names and non-essential ones. If your critical titles have exceeded the norm, then think about changing the hard drive.
She is Russian and less functional.
We also pay attention to temperature. I've been doing an experiment about this, ssd is on my side wall (at zalman cases there is a special mount), and second hard the disk is in its place, and there is also a cooler in front, which additionally cools it. So, with and without a cooler, the difference is 4 degrees. So I will move the ssd closer to the cooler. After all, when a hard drive fails, the first reason is temperature.
Critical values
Pay special attention to the following parameters:
- 01 (01) Raw Read Error Rate- how often errors occur when reading from a data disk.
- 03 (03) Spin-Up Time- how fast the plate will unwind from the state of rest to the working state.
- 05 (05) Reallocated Sectors Count- the number of reassigned sectors. If the number of reassigned sectors ends, then will appear.
- 07 (07) Seek Error Rate- if the head is not exactly on the track, this indicates damage to the mechanics. This may be due to overheating. The more often the head misses a track, the higher the value.
- 10 (0A) Spin-Up Retry Count- also in case of mechanical failure. The error appears when the disk cannot spin up to operating speed.
- 196 (C4) Reallocation Event Count- how many reassignments were made bad sectors to reserve.
- 197(C5)Current Pending Sector Count (unstable sectors)- How many sectors are applicants for reassignment. These sectors are not yet broken, but they have a weak response.
- 198 (C6) Uncorrectable Sector Count- due to corrupted mechanics, shows the number of failed times to read sectors.
- 220 (DC) Disk Shift- due to impact, the plates can be knocked off the axis.
That's all. Not critical errors and description you will find by downloading in the document above. This is how you can check the health of your hard drive using these 2 programs. Which one to use is up to you.